เราได้เห็นเทคโนโลยีทางด้าน AI ที่กำลังก้าวไปข้างหน้าอย่างรวดเร็ว ทั้งรถที่ขับเคลื่อนได้อัติโนมัติ หรือ AlphaGo ที่สามารถเล่นเกมโกะ ชนะมนุษย์ได้ แต่มีอีกศาสตร์แขนงหนึ่งที่กำลังน่าสนใจที่นำ AI มาช่วยคือ AI กำลังมาช่วยเหล่านักดาราศาสตร์แก้ปัญหาเรื่องความลึกลับของจักรวาลของเรา
แรกเริ่มนั้น AI ถูกใช้ในภารกิจในการค้นหาดาวเคราะห์นอกระบบสุริยะ ซึ่งหนึ่งในนั้นคือภารกิจของ Nasa Kepler Mission ในการนำเครื่องมือ Kepler-90 Solar system ไปยังดาวเคราะห์ 8 ดวง ซึ่งพบว่าในระบบสุริยะที่พบนั้นมีหนึ่งในนั้นรูปแบบคล้ายกับโลกมนุษย์เรา
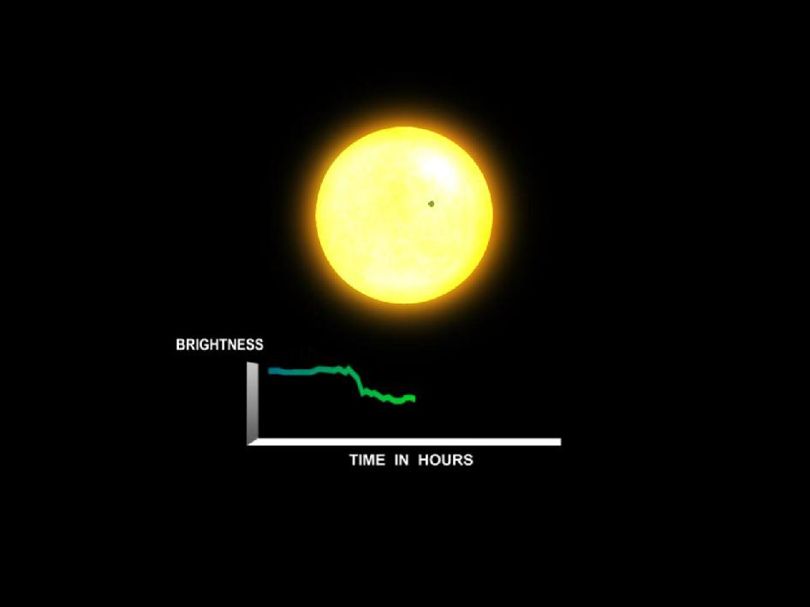
When a planet crosses in front of its star as viewed by an observer, the event is called a transit. Transits by terrestrial planets produce a small change in a star’s brightness of about 1/10,000 lasting for 2 to 16 hours. Credit NASA
ต้องบอกว่ากระแสของ AI นั้นมาแรงจริง ๆ ในช่วงนี้ ทำให้ผู้ที่เกี่ยวข้องที่เป็นบุคลลากรด้าน AI ทั้งนักวิจัย รวมถึงวิศวกรต่าง ๆ ที่มีความสามารถทางด้าน AI เป็นที่ต้องการจากบริษัทยักษ์ใหญ่ของ silicon valley ไม่ว่าจะเป็น google , microsoft , apple หรือ facebook ซึ่งล้วนแล้วต่างมี project ที่เกี่ยวข้องกับ AI กันแทบทั้งสิ้น
ต้องบอกว่าการแข่งขันทางด้านการแย่งตัวบุคคลากรนั้น ค่อนข้างรุนแรง เนื่องจากมีพนักงานที่มีคุณสมบัติด้าน AI ที่เป็นไปตามความต้องการของบริษัทเหล่านี้อยู่ไม่มาก จึงต้องมีการแย่งชิงตัวกัน โดยมีข้อเสนอเงินรายได้จำนวนมหาศาลเพื่อเป็นสิ่งล่อใจในการแย่งชิงตัวบุคลากรเหล่านี้
ซึ่งต้องบอกว่าเหล่าบริษัทยักษ์ใหญ่ใน silicon valley เดิมพันค่อนข้างสูงกับเทคโนโลยี AI ไล่มาตั้งแต่ ระบบการสแกนหน้าผ่าน smartphone เทคโนโลยีทางด้าน healthcare รวมไปถึง ในอุตสาหกรรมยานยนต์ ที่กำลังมุ่งสู่ยานยนต์ไร้คนขับ ซึ่งกำลังเดิมพันด้วยจำนวนเงินที่น่าตกใจ ทำให้รายได้ของพนักงานเหล่านี้สูงขึ้นตามไปด้วย
ซึ่งผู้เชี่ยวชาญด้าน AI ซึ่งรวมถึง ดอกเตอร์ที่เพิ่งจบปริญญาเอกมาใหม่ ๆ หรือแม้กระทั่งพนักงานที่มีประสบการณ์ไม่มากนัก แต่มีความรู้ด้าน AI ตามความต้องการของบริษัทยักษ์ใหญ่เหล่านี้ ก็สามารถเสนอค่าตอบแทนได้สูงถึง 300,000 – 500,000 เหรียญสหรัฐต่อปี รวมถึงให้ข้อเสนอทางด้านหุ้น เพื่อเป็นสิ่งล่อใจให้กับบุคคลากรเหล่านี้ให้เข้ามาอยู่กับบริษัทตัวเองให้ได้
สำหรับผู้ที่มีประสบการณ์การทำงานใน field AI มาบ้างแล้วนั้นก็ได้ค่าตอบแทนที่สูงขึ้นไปอีกในหลักล้านเหรียญสหรัฐต่อปี รวมถึงจำนวนหุ้นที่เป็นข้อเสนอก็จะมีจำนวนมากตามประสบการณ์ของพนักงานคนนั้น ๆ และรูปแบบการต่อสัญญานั้นบางครั้งก็คล้าย ๆ กับนักกีฬาอาชีพเลยก็ว่าได้ ซึ่งสามารถเรียกค่าตอบแทนเพิ่มมากขึ้นในการต่อสัญญาใหม่ โดยสัญญาอาจจะเป็นระยะสั้น เพื่อให้สามารถต่อรองเรื่องสัญญาใหม่ได้เร็วขึ้นนั่นเองเพราะมีหลายบริษัทที่คอยจะฉกตัวกันไปอยู่แล้ว เพราะความต้องการใน domain ดังกล่าวนั้นมีล้นมาก แต่บุคคลากรยังไม่พอต่อความต้องการ
ยิ่งไม่ต้องพูดถึงในระดับผู้บริหารที่มีประสบการณ์กับโครงการ AI นั้น บางรายอาจจะมีปัญหาถึงกับต้องเข้าสู่กระบวนการศาลกันเลยทีเดียวเช่น ในกรณีของ Anthony Levandowski ซึ่งเป็นลูกจ้างเก่าของ google ที่ได้เริ่มงานกับ google มาตั้งแต่ปี 2007 ได้รับค่าแรงจูงใจหรือ incentive ในการไปเซ็นสัญญาเข้าร่วมงานกับบริษัท Uber กว่า 120 ล้านเหรียญสหรัฐ ซึ่งต้องทำให้ทั้ง google และ Uber ต้องมีปัญหาขึ้นโรงขึ้นศาลกันเนื่องมาจากปัญหาเรื่องทรัพย์สินทางปัญญาที่อาจจะถูกละเมิดได้
Anthony Levandowski
มีปัจจัยเร่งไม่กี่อย่างที่ทำให้อัตราการจ่ายค่าจ้างของบุคคลากรด้าน AI นั้นถีบสูงขึ้นอย่างรวดเร็ว หนึ่งในนั้นคือ การแย่งตัวจาก อุตสาหกรรมรถยนต์ ที่กำลังพัฒนาในส่วนรถไร้คนขับ ซึ่งต้องการบุคคลากรแนวเดียวกันกับที่บริษัทยักษ์ใหญ่ทางด้าน internet ใน silicon valley ต้องการ ซึ่งส่วนของบริษัททางด้าน internet อย่าง facebook หรือ google นั้นต้องการแก้ปัญหาหลายอย่างที่ต้องใช้ AI ในการแก้เช่น การสร้างผู้ช่วย digital สำหรับ smart phone หรือ IoT device ที่อยู่ภายในบ้าน หรือการคัดกรองเนื้อหา content ที่ไม่เหมาะสมในระบบก็ต้องอาศัย AI ในการช่วยคัดกรอง ซึ่งการแก้ไขปัญหาเหล่านี้นั้นไม่เหมือนกับการสร้าง application mobile ธรรมดา ๆ ที่สามารถหาบุคคลากรได้ไม่ยาก แต่ต้องอาศัยความเชี่ยวชาญในด้าน AI เพื่อช่วยแก้ปัญหาเหล่านี้ให้ง่ายขึ้น
ส่วนบางรายก็ใช้รูปแบบการประนีประนอม Luke Zettlemoyer จาก University of Washington ได้มารับตำแหน่งที่ห้องทดลองทางด้าน AI ของ google ในเมือง ซีแอตเติล ซึ่งสามารถจ่ายเงินให้มากกว่าสามเท่าของรายได้เดิมของ Luke โดย google อนุญาติให้เขาสามารถสอนหนังสือต่อได้ที่ Allen Institute
แต่เหล่าบริษัทยักษ์ใหญ่ อย่าง google , facebook หรือ Microsoft ก็ได้ทำการเปิดห้องทดลองด้าน AI ในต่างประเทศ เช่น Microsoft นั้นได้เปิดขึ้นที่ แคนาดา ส่วน google นั้นก็มีการจ้างงานเพิ่มขึ้นในประเทศจีนเหมือนกัน
ซึ่งสาเหตุต่าง ๆ เหล่านี้ล้วนแต่ทำให้ไม่แปลกใจว่าการขาดแคลนบุคคลากรด้าน AI นั้นคงจะไม่บรรเทาลงไปในเร็ว ๆ วันนี้อย่างแน่นอน เพราะการสร้างบุคคลากรด้านนี้ขึ้นมานั้นไม่ใช่เรื่องง่ายแต่อย่างใด มหาลัยที่เชี่ยวชาญที่สามารถสร้างบุคลากรที่มีคุณภาพออกได้ก็มีไม่มาก ซึ่งส่วนใหญ่ก็อยู่ในสหรัฐอเมริกา ซึ่งจากสาเหตุที่ demand และ supply ของบุคคลากรด้าน AI ยังไม่สมดุลในขณะนี้ ก็มีแนวโน้มที่รายได้ของบุคคลากรในด้านนี้ก็จะยังคงสูงขึ้นต่อไปเรื่อย ๆ อย่างแน่นอน
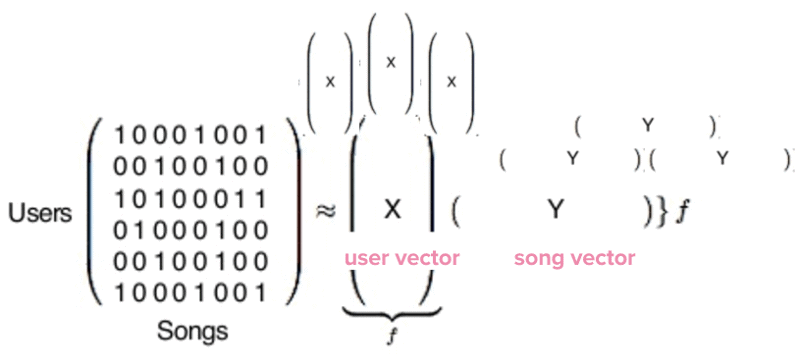
ซึ่ง Python Library นั้นจะ run matrix ทั้งหมดโดยใช้สมการคือ
สมการ python
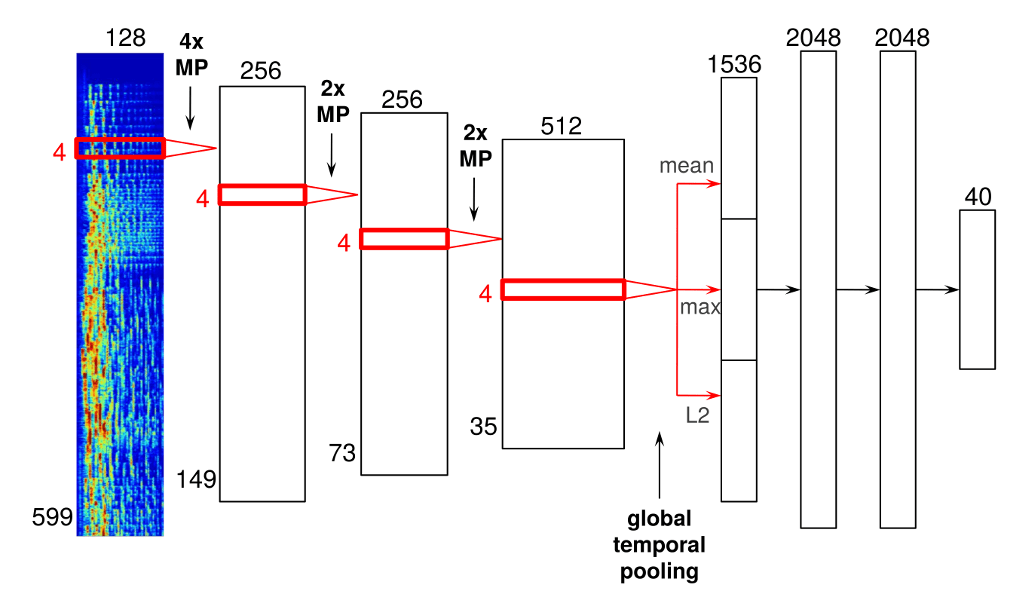
ซึ่งเมื่อ run จบนั้น จะได้รูปแบบของ Vectors สองชนิดคือ X จะแทน user vector ซึ่งจะหมายถึง รสนิยมการฟังเพลงของ single นั้น ๆ ของ user ส่วน Y นั้นจะเป็น song vector จะเป็นตัวแทนของ profile ของเพลงนั้น ๆ
The User/Song matrix produces two types of vectors: User vectors and Song vectors
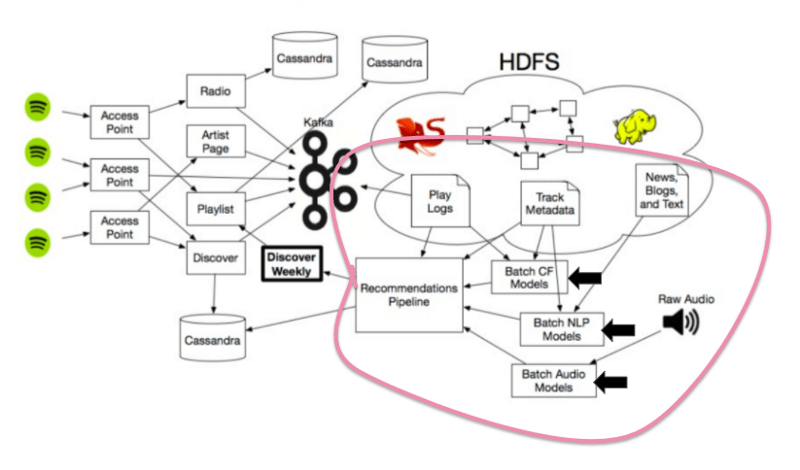
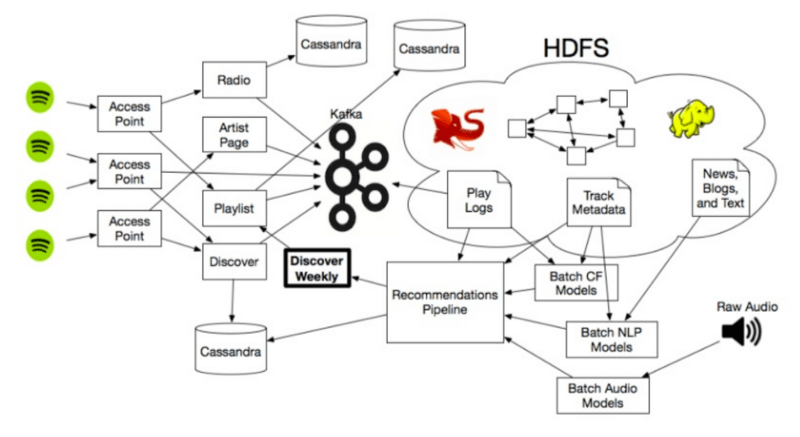
ซึ่งเราจะได้ User Vectors จำนวน 140 ล้านตามจำนวน user ทั้งหมดในระบบ และ Song Vectors จำนวน 30 ล้าน ตามจำนวนเพลงทั้งหมดในระบบ ซึ่งเหล่า Vector ข้อมูลเหล่านี้นั้น เป็นประโยชน์อย่างยิ่งในการเปรียบเทียบรสนิยมการฟังเพลงของ user แต่ละคน ซึ่งการที่จะหาว่า user คนใด ๆ มีรสนิยมการฟังเพลงคล้ายกับใครนั้น จะต้องใช้ collaborative filtering ในการเปรียบเทียบ vector ของ user นั้น ๆ กับ vector ของคนอื่น ๆ ในระบบทั้งหมด ซึ่งเมื่อใช้ computer algorithm ทำการเปรียบเทียบทั้งหมด เราก็จะได้เห็นว่าใครมีรสนิยมการฟังเพลงคล้ายกัน เช่นเดียวกับในส่วนของ Song Vector เราก็ต้องนำ song vector ของเพลงนั้น ๆ ไปเปรียบเทียบหาจาก song vector ของเพลงทั้งหมดในระบบ ก็จะได้เพลงที่มีสไตล์คล้าย ๆ กัน ถึงแม้ว่าจากตัวอย่างที่ผ่านมานั้น collaborative filtering นั้นสามารถที่จะให้ผลลัพธ์ที่น่าสนใจ แต่ spotify ก็รู้ว่าเค้าต้องทำอะไรได้ดีกว่าการใช้ engine รูปแบบเดียวกับบริการอื่น ๆ เพียงอย่างเดียว
Recommendation Model #2 : Natural Language Processing (NLP)
สำหรับส่วนที่ 2 ใน Recommendation Model ของ Spotify นั้นใช้ เทคนิค ของ Natural Language Processing (NLP) สำหรับ source ของข้อมูลที่จะนำมา analyse ผ่านเทคนิค NLP นั้นจะใช้ ข้อมูลของ track metadata ของเพลง , news articles, blogs รวมถึงข้อมูลที่เป็น text อื่น ๆ ในระบบ internet
Natural Language Processing (NLP)
Natural Language Processing นั้น จะเป็นการใช้ความสามารถของ computer ในการวิเคราะห์ข้อความ text โดยส่วนใหญ่นั้นจะใช้วิธีผ่าน sentiment analysis APIs ซึ่งผมได้เคยเขียน blog การวิเคราะห์ Market Trend ของหุ้น โดยใช้ปัจจัยพื้นฐานด้านข่าวซึ่งจะใช้เทคนิคคล้าย ๆ กันคือ sentiment analysis เพื่อไปวิเคราะห์ market trend ของหุ้น
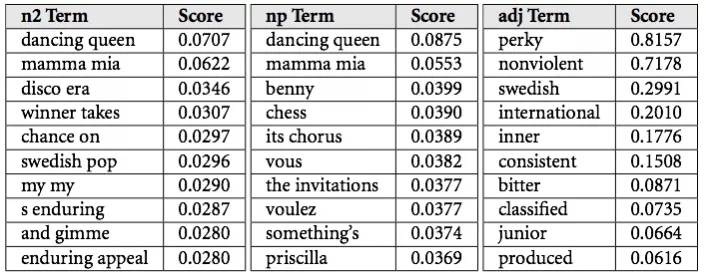
โดยรูปแบบการทำงานเบื้องหลังของ NLP ที่ spotify ใช้นั้น spotify จะสร้าง crawls คล้าย ๆ กับที่ google ใช้ในการเก็บ index ข้อมูล data เพื่อมา index ให้ user ทำการค้นหา แต่ spotify นั้นจะ focus ไปที่ blogs หรือ งานเขียน ที่เกี่ยวข้องกับวงการเพลง และนำมาวิเคราะห์ว่าผู้คน ใน internet กำลังพูดถึง ศิลปิน หรือ เพลงนั้นๆ อย่างไร แต่วิธีการในการ process ข้อมูลเหล่านี้นั้นยังเป็นความลับที่ spotify ยังไม่มีการเผยแพร่ออกมาว่าจัดการกับข้อมูลเหล่านี้อย่างไร แต่จะขอยกตัวอย่างจาก Echo Nest ที่ใช้วิธีการคล้าย ๆ กัน ซึ่ง Echo Nest นั้้นนำข้อมูลมา process โดยเรียกว่า “cultural vectors” หรือ “top terms” โดยแต่ละ ศิลปิน รวมถึง แต่ละเพลงนั้น จะมีการเปลี่ยนแปลงของ top-terms อยู่ทุกวันผ่านการ analysis ข้อมูลจากระบบ internet ซึ่งแต่ละ term นั้นจะมีค่า weight อยู่ ขึ้นอยู่กับความสำคัญของคุณลักษณะของแต่ละ term
“Cultural vectors” , or “top terms” , as used by the Echo Nest.
หลังจากนั้น รูปแบบก็จะคล้าย ๆ กับ collaborative filtering ซึ่ง NLP Model จะใช้ terms และ weights ในการสร้าง vector ของเพลง ซึ่งสามารถที่จะนำมาเปรียบเทียบว่า เพลงใด มีสไตล์ คล้าย ๆ กับเพลงใด ซึ่งจะส่งผลต่อการแนะนำให้กับ user ที่ใช้งานได้ตรงรสนิยมของ user คนนั้น ๆ ได้
Recommendation Model #3: Raw Audio Models
Raw Audio Models
หลาย ๆ ท่านอาจจะคิดว่า แค่ 2 model ข้างต้นนั้นก็สามารถวิเคราะห์ข้อมูล ของเพลงและ user ได้อย่างมีประสิทธิภาพแล้ว แต่ Spotify ได้เพิ่มในส่วนของ Raw Audio Model เพื่อเพิ่มความแม่นยำในส่วนการแนะนำเพลงให้มีความแม่นยำมากที่สุด และ Raw Audio Model นั้นยังสามารถที่จะเปิดประสบการณ์ฟังเพลงใหม่ ๆ ให้กับ user ได้อีกด้วย
เป็นข่าวใหญ่ในช่วงสัปดาห์เลยทีเดียวสำหรับการแข่งขันเกมส์โกะ ระหว่างมนุษย์ กับ AI ของ Google โดยมีการนำแชมป์โลกโกะอย่าง Lee Sedol โดยในสามเกมส์แรก Alpha go ซึ่งเป็น AI จาก Google ที่พัฒนาโดยบริษัท Deepmind ซึ่งเป็นบริษัทลูกของ google สามารถเอาชนะไปได้ และล่าสุด Lee Sedol เพิ่งจะกลับมาชนะได้เป็นเกมส์แรกในเกมส์ที่ 4 หลังจากพ่ายแพ้ไปใน 3 เกมส์แรก
เทคโนโลยีด้าน AI นั้นได้พัฒนามาในระดับที่สามารถแก้ไขปัญหาที่ซับซ้อนได้ อย่างการเล่นเกมส์ที่มีความซับซ้อน และเง่ื่อนไขการเล่นที่มีความน่าจะเป็นจำนวนมากอย่างเกมส์โกะได้ ถือว่าเป็นเรื่องไม่ธรรมดา โดยในปัจจุบันนั้นมีการวิจัยค้นคว้าทั้งทางด้าน Machine Learning รวมไปถึง Neural Network ที่พัฒนาไปไกลมาก แทนที่จะเก็บความน่าจะเป็นทั้งหมด แล้วให้ AI ค้นหาทางเลือกที่ดีที่สุด ก็มีการพัฒนาให้มีการเรียนรู้เองแบบมนุษย์ทำให้ความสามารถของ AI เพิ่มมากขึ้นเป็นอย่างมากสามารถใช้ในการ Solve ปัญหาที่ยาก ๆ ได้หลาย ๆ ปัญหา
สำหรับ Alpha Go นั้นถือว่าเป็นจุดเริ่มต้นของยุคใหม่ของ AI ที่มนุษย์ทุกคนต้องตระหนักถึงเลยก็ว่าได้ ซึ่งเป็นการแสดงให้เห็นถึงก้าวกระโดดของการพัฒนา AI ที่ทำให้มนุษย์ทุกคนต้องหันมาจับตามอง เพราะมันจะมีผลกระทบต่อชีวิตของคนเรามากเป็นอย่างยิ่งในอนาคตอันใกล้นี้อย่างแน่นอน
ทำไมเราถึงต้องกลัว? การที่ google ยอมลงทุนงานวิจัยด้าน AI ในระดับมูลค่ามหาศาลผ่านการรวมตัวของ นักวิทยาศาสตร์ และ programmer กว่า 100 ชีวิตใน Deepmind นั้นถือว่าเป็นการมองถึงอนาคตที่ยิ่งใหญ่ของ google หากมีเครื่องมีที่สามารถ solve ปัญหายาก ๆได้ทุกปัญหาผ่านการใช้ AI เช่น การ trade หุ้น หากมีเครื่องมีที่สามารถชนะกลไก ของตลาดหุ้นโดยมีเป้าหมายที่ให้ผลตอบแทนสูงสุด โดยใช้ AI ในการ trade ซึ่งก็มองว่าเป็นเครื่องจักรทำเงินของ google ได้เลยทีเดียว รวมถึงด้านแขนงอื่น ๆ อย่างด้านการแพทย์ หากนำ AI ไปแก้ปัญหายาก ๆ อย่างการรักษาโรคมะเร็ง หรือ ผลิตยารักษาโรคที่ไม่สามารถรักษาได้ในปัจจุบันเพราะบางปัญหานั้น มนุษย์เรายังไม่สามารถ solve ปัญหาได้ แต่มันไม่ใช่ปัญหาของ AI แต่อย่างใด รวมถึงปัญหาที่เราสงสัยกันมานานอย่างเรื่องการเกิดของระบบจักรวาล ที่แท้จริงแล้วมีที่มาอย่างไร หรือการนำไปใช้ในการทหารผ่านหุ่นยนต์รบต่าง ๆ หรือระบบขับเคลื่อนอาศยานแบบอัตโนมัติ เหล่านี้ล้วนแล้วแต่ใช้ AI มาแก้ปัญหาได้ทั้งสิ้น
และแน่นอนทุกอย่างก็จะมีผลกระทบต่อชีวิตมนุษย์เราทุกคนในอนาคตอย่างแน่นอน หาก google มีเครื่องมือเหล่านี้อยู่ในมือก็สามารถสร้างประโยชน์ได้มหาศาลจากเครื่องมือดังกล่าวทั้งในด้านบวกและด้านลบ และ google ก็จะคืบคลานเข้าสู่เทคโนโลยีด้านอื่น ๆ ที่เกี่ยวข้องกับชีวิตประจำวันของเราโดยผ่านเครื่องมือด้าน AI ที่มีอยู่ในมือ และนี่คงไม่เป็นการมองที่เว่อร์เกินไป เพราะ ณขณะนี้ AI มันเริ่มเข้ามาใกล้ตัวเรามากขึ้นจริง ๆ