เนื่องจากในตอนเรียนปริญญาโท ผมได้มีโอกาสที่จะทำงานวิจัยที่เกี่ยวข้องกับการใช้ machine learning ในการวิเคราะห์การตรวจหามะเร็งเต้านมของผู้หญิง รวมถึงในปัจจุบันผมงานของตัวผมเองก็อยู่ใน domain นี้โดยตรง ซึ่งแม้จะเป็นเวลาหลายปีมาแล้ว แต่ช่วงนี้กระแสของ AI รวมถึง Machine Learning กำลังมาแรง จึงขอจะกล่าวถึงซักหน่อย รวมถึง algorithm ที่ผมเลือกใช้คือ Support Vector Machine เริ่มถูกพูดถึงในหลาย ๆ วงการแม้กระทั่งวงการ trading เนื่องจากมีความแม่นยำในการจำแนกค่อนข้างสูง
ปัจจุบันนั้นโรคมะเร็งเต้านมกำลังเป็นปัญหาทางสาธารณสุขของทุกประเทศทั่วโลก เนื่องจากโรคมะเร็งเป็นโรงที่ร้ายแรงที่คุกคามชีวิตมนุษย์โดยไม่เลือกเพศและวัยนอกจากนี้โรคมะเร็งเป็นโรคเรื้อรัง ที่ต้องใช้เวลาในการรักษานาน ทำให้ผู้ป่วยเกิดความทุกข์ทรมาน มีค่าใช้จ่ายสูง และยังคุกคามความเป็นอยู่ของครอบครัว ในปัจจุบันนั้นโรคมะเร็งจึงเป็นสาเหตุการตายอันดับต้น ๆ ของประชากรโลก ซึ่งรวมถึงประชากรในประเทศไทย มะเร็งเป็นโรคที่เกิดขึ้นกับเซลหลายชนิด หลายอวัยวะ

ซึ่งเต้านมเป็นอวัยวะหนึ่งในอวัยวะเพศหญิงที่มีอัตราการเป็นมะเร็งได้ค่อนข้างสูง ในประเทศไทยก็พบว่ามีผู้ป่วยมะเร็งเต้านมในอัตราที่สูง และมีแนวโน้มสูงขึ้นเรื่อย ๆ ซึ่งอัตราการเติบโตของมะเร็งเต้านมในไทยนั้นได้มีการเพิ่มปริมาณขึ้นอย่างรวดเร็วซึ่งสอดคล้องกับการเติบโตของโรคนี้ในประชากรทั่วโลก และเป็นโรคมะเร็งที่เกิดขึ้นมากที่สุดในเพศหญิง และอัตราการเสียชีวิตก็เพิ่มขึ้นในอัตราที่รวดเร็วเช่นกัน

ในปัจจุบันยังไม่มีวิธีการใดที่สามารถรักษาโรคนี้ได้อย่างมีประสิทธิภาพเพียงพอ ซึ่งการตรวจหาผ่านการ X-Ray จึงเป็นปัจจัยสำคัญในการรักษาโรค และปรับปรุงอัตราการรอดตายที่เกิดขึ้นจากโรคมะเร็งเต้านม ซึ่งในปัจจุบันนั้นวิธีการที่มีความน่าเชื่อถือที่สุดในการตรวจหามะเร็งเต้านมนั้น คือ การวินิจฉัยผ่านคลังข้อมูลภาพทางการแพทย์ ที่มีการเก็บอย่างมีประสิทธิภาพ จากคลังข้อมูลที่มีขนาดใหญ่ ซึ่งระเบียบวิธีขั้นตอนดังกล่าวนั้นสามารถช่วยเร่งกระบวนการในการวินิจฉัยโรคได้อย่างรวดเร็ว แต่ก็ยังมี limit อยู่กับความสามารถของแพทย์ที่ไม่เท่าเทียมกัน รวมถึง แพทย์ที่ expert จริงๆ ด้านนี้ยังมีอยู่น้อยมาก รวมถึงความแม่นยำในการวินิจฉัยนั้นยังมีข้อจำกัดอยู่ถ้าเทียบกับประสิทธิภาพของ AI
Support Vector Machine คืออะไร
Support Vector Machine เป็นตัวแบบที่ใช้ในการระบุตัวบุคคลหรือ object โดย SVM จะทำการแบ่งชั้นของข้อมูลด้วยระนาบหลายมิติ จากข้อมูล 2 กลุ่มชุดข้อมูล โดยตัวแบบของ SVM เกี่ยวข้องกับเครือข่ายประสาทเทียม ซึ่งโดยอันที่จริงแล้วตัวแบบของ SVM ใช้ Sigmoid Kernel Function ซึ่งมีค่าเท่ากันทั้ง 2 เลเยอร์เป็นตัวแบบที่ใช้ในการระบุตัวบุคคล โดย SVM จะทำการแบ่งชั้นของข้อมูลด้วยระนาบหลายมิติ จากข้อมูล 2 กลุ่มชุดข้อมูล โดยตัวแบบของ SVM เกี่ยวข้องกับเครือข่ายประสาทเทียม

ซึ่งโดยอันที่จริงแล้วตัวแบบของ SVM ใช้ Sigmoid Kernel Function ซึ่งมีค่าเท่ากันทั้ง 2 เลเยอร์ ตัวแบบของ SVM มีความคล้ายคลึงกับเพอร์เซฟตรอนซึ่งเป็นข่ายงานประสาทเทียมแบบง่ายมีหน่วยเดียวที่จำลองลักษณะของเซลล์ประสาท ด้วยการใช้ Kernal Function
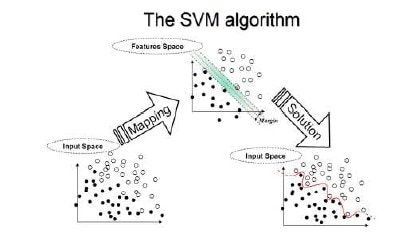
โดยใน paper ที่ตีพิมพ์เกี่ยวกับ SVM นั้นจะเรียกตัวแปรในการตัดสินใจว่า คุณสมบัติและตัวแปรที่เปลี่ยนแปลงใช้ในการกำหนดระนาบหลายมิติ ซึ่งเรียกว่า โครงสร้าง (feature) ส่วนการเลือกที่มีความเหมาะสมที่สุดเรียกว่า โครงสร้างในการคัดเลือก (feature selection) จำนวนเซตของโครงสร้างที่ใช้อธิบายในกรณีหนึ่ง (เช่น แถวของการค่าที่เราคาดการณ์) เรียกว่า เวกเตอร์ (vector) ดังนั้นจุดมุ่งหมายของตัวแบบ SVM คือการประโยชน์สูงสุดจากระนาบหลายมิติที่แบ่งแยกกลุ่มของเวกเตอร์ในกรณีนี้ด้วยหนึ่งกลุ่มของตัวแปรเป้าหมายที่อยู่ข้างหนึ่งของระนาบ และกรณีของกลุ่มอื่นที่อยู่ทางระนาบต่างกัน ซึ่งเวกเตอร์ที่อยู่ข้างระนาบหลายมิติทั้งหมดนี้เราจะเรียกว่า ซัพพอร์ตเวกเตอร์ (Support Vectors)
Atrribute Reduction based on Atribute Importance Function

มี paper หลายตัวที่นำเสนอการใช้ Support Vector Machine ในการวิเคราะห์ มะเร็งเต้านม ซึ่งให้ค่าความแม่นยำไม่ต่างกันเท่าไหร่ในหลากหลายวิธี แต่ในตอนนั้นผมสนใจในเรื่องการ Improve Attribute base on Inportance Function ซึ่งเป็นการกรองคุณสมบัติ หรือ features ที่เป็นขยะออกไปให้มากที่สุด เนื่องจากเราใช้ค่าทางสถิติหลายอย่างในการจำแนก ซึ่งบางค่านั้นแทบจะไม่มีผลต่อความแม่นยำในการจำแนกผลเลยด้วยซ้ำ เทคนิค นี้ก็ทำเพื่อแยก คุณสมบัติที่มีผลต่อความแม่นยำจริง ๆ ให้ได้มากที่สุด ก่อนนำไป training
ซึ่งผมได้สนใจเป็นพิเศษในงานวิจัย An Improved Attribute Reduction Algorithm based on Attribute Importance function ได้นำเสนอวิธีในการลดคุณลักษณะของข้อมูลโดยปรับปรุงส่วนของ Discernibility Matrix ของ Attribute โดยจะพิจารณาจากฟังก์ชั่นที่สำคัญ เมื่อนำข้อมูลมาแปลงในรูปแบบของ Binary Discernibility Matrix รวมกับการคุณสมบัติการลดคุณลักษณะโดยใช้ Rough Set Theory โดยจะลดคุณลักษณะที่ไม่จำเป็นออกโดยใช้ฟังก์ชันสำคัญของคุณลักษณะที่ได้ทำการปรับปรุงผ่าน ของ Matrix ซึ่งจะสามารถทำให้มีประสิทธิภาพที่ดีขึ้น
โดยการพิสูจน์ทำโดยวิเคราะห์ความเปรียบต่าง (contrast) ซึ่งเมื่อมองใน time complexity นั้นจะมีประสิทธิภาพกว่างานวิจัยพื้นฐานของการใช้ Rough Set Theory ในการลดคุณลักษณะของข้อมูล วิธีการลดคุณลักษณะของ Matrix Binary Discernibility ซึ่งแม้ว่าคุณลักษณะที่ตรงกับคอลัมน์ใน Matrix ที่มีค่า “1” จำนวนมากนั้น ซึ่งในหลาย ๆ งานวิจัย แสดงให้เห็นว่าสามารถลดส่วนที่ไม่จำเป็นออกไปได้โดยมองจาก Importance Function ซึ่งมองที่ จำนวนการเกิดของคุณลักษณะ และ ความยาวขององค์ประกอบของ Discernibility Binary Matrix ซึ่งจะได้ค่าฟังก์ชั่นดังนี้
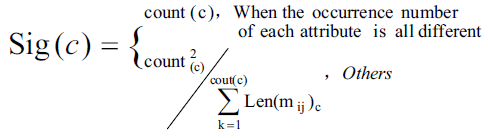
เมื่อ mij คือ Binary Discernibility Matrix ซึ่งได้จากการแปลงข้อมูลที่เราสนใจโดยใช้การDicretizationซึ่งจากสมการนั้น Count(c) หมายถึงจำนวนรวมของ c attribute ที่ปรากฏใน matrix Len c (mij) คือความยาวขององค์ประกอบใน matrix ที่มีคุณสมบัติ c
จากสมการจะได้ค่าตามอัตราส่วนของจำนวนลักษณะที่ปรากฏ และความยาวเฉลี่ยของ matrix ที่มีคุณสมบัติ c ซึ่งหมายความว่าถ้าการเกิดขึ้นของสองลักษณะที่แตกต่างกันจำนวนมาก ทำให้คุณลักษณะนั้นปรากฏมากขึ้น ซึ่งส่วนที่สำคัญในการลดคุณลักษณะคือ คุณสมบัติที่มีจำนวนการเกิดที่โดดเด่นของข้อมูลที่มีคุณลักษณะ c
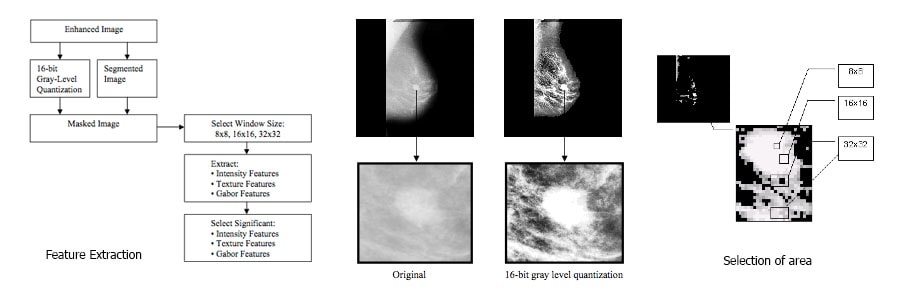
Feature extraction and Selection
คุณสมบัติด้าน Texture ได้รับการพิสูจน์จากงานวิจัยหลาย ๆ ชิ้น แล้วว่ามีประโยชน์ในเรื่องการจำแนกความแตกต่างของมวลและเนื้อเยื่อของเต้านมปกติใน digital mammograms ซึ่งสามารถแยกความปกติและผิดปรกติของเนื้อเยื่อรวมถึง microcalcifications ซึ่งคุณสมบัติด้าน Texture นั้นจะทำการจำแนกโดยใช้ Gray level co-occurrence matrices (GLCM) ซึ่ง matrices นั้นจะถูกสร้างจากระยะทาง d=1 และทิศทางของθให้เป็น 0 °, 45 °, 90 ° และ 135 °
ซึ่งการใช้เพียงทิศทางเดียวอาจจะไม่เพียงพอและทำให้ข้อมูลที่จำแนกมีความน่าเชื่อถือได้ด้วยเหตุนี้การใช้สี่ทิศทางจะใช้ในการจำแนกข้อมูล Texture ของแต่ละพื้นที่ใน digital mammograms ซึ่งการอธิบายค่าของ Texture จาก GLCM นั้นจะมีค่าที่เกี่ยวข้องคือ Contrast , energy , homogeneity และ correlation ของค่า gray scale ซึ่งค่า energy ที่อยู่ในบาง element ของ GLCM นั้น สามารถอ้างได้ถึงรูปแบบของการเกิดก้อนเนื้อ ส่วนค่าของ Homogeneity นั้นจะสามารถอ้างได้ถึงการกระจายตัวขององค์ประกอบใน GLCM ส่วนค่า Correlation นั้น จะแสดงถึงความสัมพันธ์ของ pixel ที่อยู่ใกล้เคียงกันของ image ซึ่งจากงานวิจัยส่วนใหญ่ นั้นใช้ฐานข้อมูลส่วนใหญ่ในขนาด 32*32 และใช้ขนาดเล็กสุดที่ 8*8 ซึ่งสามาถแสดงรายละเอียดดังนี้
Gray-level co-occurrence matrix (GLCM)
Gray-level co-occurrence matrix (GLCM) นิยมใช้เป็นอย่างมากในการวิเคราะห์โครงร่างของภาพ เนื่องจากโครงร่างของภาพเป็นคุณลักษณะที่สามารถมองเห็นได้โดยตรงจากภาพ ดังนั้น ในการพิจารณาโครงร่างของภาพจากค่าระดับเทาจะต้องใช้เมตริกซ์ ขนาด 2 มิติ gray-level co-occurrence matrix เป็นเมตริกซ์ 2 มิติ ซึ่งพิจารณาได้ จากการเกิดค่าระดับเทาซํ้าๆ กันในโครงร่างของภาพ (คุณสมบัติดังกล่าวเปลี่ยนแปลงตามระยะทางอย่างรวดเร็วในโครงร่างที่ละเอียด และเปลี่ยนแปงอย่างช้าๆ ในโครงร่างที่หยาบ) สำหรับการวิเคราะห์ส่วนที่เป็นโครงร่างของภาพจะใช้เมตริกซ์จัตุรัสที่มีขนาด M×M (M เป็นจำนวนค่าระดับเทาของภาพ) มาคํานวณ การเกิดค่าระดับเทาซํ้าๆ กันสามารถอธิบายได้ด้วยเมตริกซ์ที่มีความถี่ที่ สัมพันธ์กันซึ่งเขียนแทนได้ด้วย Pd,r(i,j) ซึ่งแทนความถี่ในการเกิดค่าระดับเทาที่ i และ j ในวินโดวส์ที่พิจารณา ด้วยระยะห่างเท่ากับ d ที่ทิศทาง r ความถี่ ของ gray-level co-occurrence matrix สามารถเขียนเป็นฟังก์ชันใน 4 ทิศทางที่ระยะทาง d ใดๆได้ดังนี้
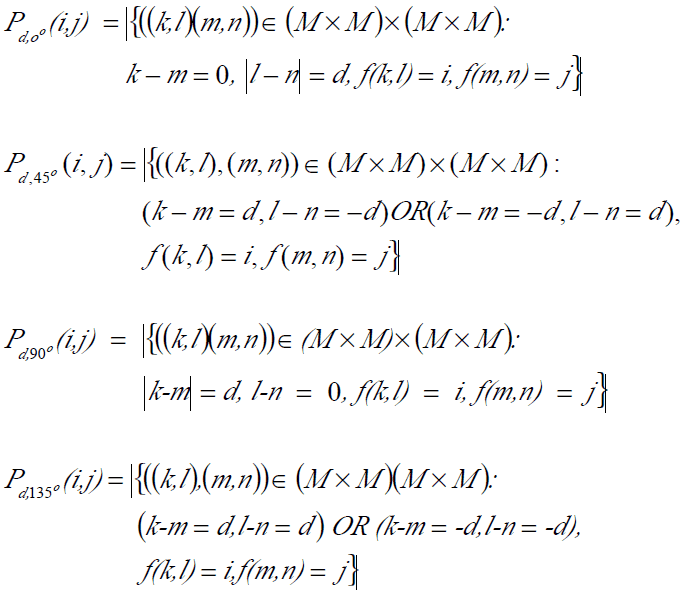
เมื่อ |{…}| แทนเซตของค่าที่เป็นไปได้ตามเงื่อนไข
การจําแนกโครงร่างสามารถทําได้ด้วยการใช้เกณฑ์ในการพิจารณาลักษณะโครงร่างของพื้นผิวภาพ บางประการที่ได้จาก co-occurrence matrix ดังต่อไปนี้
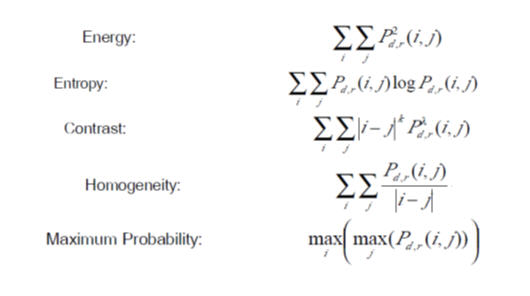
ในหลาย ๆ งานวิจัย นั้นใช้การทำ pre-processing image ก่อนที่จะนำมาใช้ในการจำแนก โดยคุณสมบัติของการจำแนกนั้นจะมาจากฐานข้อมูล ซึ่งฐานข้อมูลดังกล่าวนั้นสามารถสร้างโดยการรวบรวมคุณลักษณะที่มีอยู่แล้วบางชนิด เช่น ชนิดของเนื้อเยื่อ (ความหนาแน่นของไขมัน และ ต่อมไขมัน ) และตำแหน่งที่มีความผิดปรกติ ( เช่น จุดศูนย์กลางของวงกลมรอบเนื้องอก) ที่ทำการจำแนกโดยคุณสมบัติ 4 อย่างทางสถิติ คือ mean, variance, skewnessและ kurtosis ซึ่งใช้สูตรสำหรับการคำนวณค่าทางสถิติแต่ละค่าดังนี้

ซึ่ง N หมายถึงจำนวน Gray Level ในภาพเต้านมโดย fk เป็นระดับสีเทา ที่ nk คือจำนวน pixel ที่ fk เป็น Gray Level และ n คือ จำนวน pixel ทั้งหมด
ซึ่งคุณสมบัติการจำแนกนั้นจะมีการคำนวณใน windows ที่มีขนาดเล็กของรูปต้นฉบับ โดยที่จะนำรูปต้นฉบับนั้นมาแบ่งเป็นสี่ส่วน เพื่อเพิ่มประสิทธิภาพในการจำแนกผล ซึ่งค่าสถิติต่าง ๆ ที่ได้ทำการคำนวณใน 16 ส่วนย่อยนั้น จะได้ค่าคุณสมบัติทั้งหมด 64 ค่าของแต่ละ image โดยจะนำค่าดังกล่าวไปประมวลผลกับเทคนิค Support Vector Machine เป็นลำดับต่อไป
Experiment
โดยในการทดลอง ก็จะนำเทคนิคและงานวิจัยที่เกี่ยวข้องดังกล่าวมาพัฒนาและปรับปรุง ในด้านประสิทธิภาพการทำงานทั้งในเรื่องของความแม่นยำของการจำแนก และรวมถึงประสิทธิภาพในการประมวลผลข้อมูลให้ดียิ่งขึ้น โดยการทดลองจะเน้นที่การปรับปรุงส่วนของการคัดเลือกคุณลักษณะที่เหมาะสม เพื่อให้ SVM algorithm ทำงานได้อย่างมีประสิทธิภาพมากขึ้น ซึ่งจากงานวิจัย ก่อนหน้านั้นจะเห็นได้ถึงแนวทางในการปรับปรุงการคัดเลือกคุณลักษณะที่เหมาะสมโดยมองที่ฟังก์ชั่นสำคัญ ซึ่งจะเป็นการลดคุณลักษณะของข้อมูล และเมื่อเปรียบเทียบกับการใช้ Rough Set Theory แบบ General Model หรือ การใช้ Genetic algorithm ร่วมกับเทคนิคของ Decision Tree นั้น ก็เป็นแนวทางที่สามารถทำให้ได้ผลการทดลองมีประสิทธิภาพมากยิ่งขึ้น
ซึ่งเมื่อทำการศึกษาจุดอ่อนและจุดแข็งของแต่ละงานวิจัยที่เกี่ยวข้องกับการจำแนกภาพดิจิตอลแมมโมแกรมนั้น เราสามารถใช้เทคนิค ที่มีอยู่มาปรับใช้ได้อย่างมีประสิทธิภาพ จึงเป็นจุดที่ผมสนใจที่จะนำเทคนิคต่าง ๆ ที่เกี่ยวข้องมาปรับและเพิ่มเติมในส่วนที่เป็นข้อบกพร่องกับการทดลองให้มีประสิทธิภาพการทำงานที่ดีขึ้น และสามารถใช้กับข้อมูลจริง ที่ได้จากการทำงานจริงกับโรงพยาบาลที่มีเครื่องมือประเภท Digital Mammogram เพื่อใช้ในการวิเคราะห์รักษาและช่วยจำแนกประเภทของข้อมูลภาพเต้านม ร่วมกับผู้เชี่ยวชาญที่เป็นแพทย์ทางด้านรังสีวิทยาได้อย่างมีประสิทธิภาพมากยิ่งขึ้น
ซึ่งจากงานวิจัยที่เกี่ยวข้องนั้นสามารถนำมาปรับปรุงการคัดเลือกคุณลักษณะเพื่อเพิ่มประสิทธิภาพโดยใช้เทคนิคของ Reduction Attribute based on important function เพื่อปรับปรุงความแม่นยำและประสิทธิภาพการทำงานของการคัดเลือกและจำแนกโดยใช้ SVM Algorithm กับภาพประเภทดิจิตอลแมมโมแกรมซึ่งมี วิธีการดังนี้
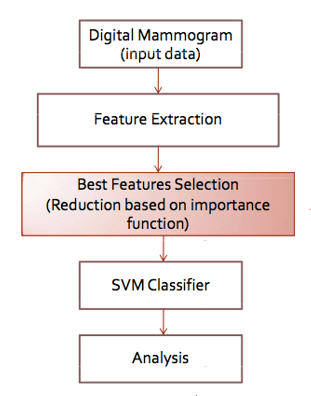
ส่วนของ input data นั้นผมจะใช้ภาพดิจิตอลแมมโมแกรมจาก MIAS ( Mammogram Image Analysis Society) ซึ่งเป็นข้อมูลที่ใช้เป็นมาตรฐานของงานวิจัยที่ยอมรับในปัจจุบันและจากงานวิจัยที่เกี่ยวข้องกับการทำ Feature Extraction ของดิจิตอลแมมโมแกรมนั้น จะใช้เทคนิคของ GLCM ในการ extract features ซึ่งจะได้ค่า features ที่มีประสิทธิภาพในการจำแนกผลที่ให้ความแม่นยำสูง
รวมถึงค่า features ทางด้านสถิติต่าง ๆ เพื่อเข้าสู่กระบวนการ Features Selection โดยใช้พื้นฐานของงานวิจัยในด้านการลดคุณลักษณะ ( Reduction Attribute based on important function) โดยจะมีการแก้ไขข้อจำกัดในเรื่องของ significant weight ที่จากงานวิจัยตัวอย่าง นั้นจะมีข้อจำกัดในข้อมูลที่ทำการ discretization ออกมาแล้ว Matrix เหลือขนาดเล็กเกินไปทำให้การคำนวณค่า significant weight
จากงานวิจัยตัวอย่าง นั้นจะมีการเลือกค่า Attribute ที่ตัดไปนั้นอาจจะมีผลต่อความแม่นยำในการจำแนก เพราะ สาเหตุของการเลือกค่า significant weight ที่มีค่ามากที่สุด ที่มีหลายค่านั้นทำให้ต้องมีการเลือกเพียง attribute เพียงตัวเดียว และ หากมีการเลือกตัวใดตัวหนึ่ง ก็จะมีผลต่อการเลือกในตัวต่อไป ซึ่งจะได้ผลการจำแนกที่แตกต่างกันเนื่องจากการเลือกลด Attribute ตัวใดไปแล้วจะมีผลต่อการเลือก Attribute ตัวถัดไปทันทีซึ่งถือเป็นจุดอ่อนของงานวิจัยชิ้นดังกล่าว

Experiment Results
ผมใช้เทคนิคการตรวจสอบ 10 fold cross validation techniques เพื่อประเมินประสิทธิภาพของอัลกอริทึม และได้ทำการแบ่งฐานข้อมูลคุณลักษณะใน 10 แบบ สำหรับการแบ่งแต่ละครั้งที่เราเลือกไว้ประมาณ 90% ของชุดข้อมูลสำหรับการ training และส่วนที่เหลือสำหรับการทดสอบ นั่นคือ 288 ภาพสำหรับชุด training และ 34 ภาพสำหรับชุดทดสอบ ซึ่งฐานข้อมูลคุณสมบัติประกอบด้วยคุณสมบัติที่สกัดได้และข้อมูลที่มีอยู่ของภาพ 322 ภาพใน MIAS แอตทริบิวต์ที่เป็นตัวเลขทั้งหมดใช้วิธีการ extract features จากที่นำเสนอในหัวข้อข้างบน ผมขอเรียกการทดลองนี้เป็น ISVM เพื่อเปรียบเทียบกับ SVM แบบปรกติ ซึ่งในขั้นตอนการ training ISVM ถูกนำมาใช้กับข้อมูลการ training
จากนั้นสำหรับการจัดหมวดหมู่ในช่วงเวลาเดียวกันจำนวนของการเลือก Attributes ต่าง ๆ จะถูกบันทึกไว้โปรแกรม SVM ซึ่งมาจาก LIBSVM ซึ่งเราได้ผลการทดลองดังนี้
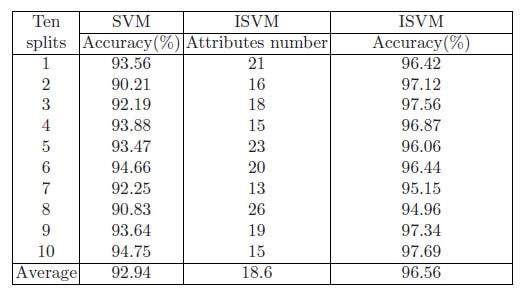

จากตาราง แสดงการเปรียบเทียบในแง่ของจำนวน Attributes ที่เลือก และการจำแนกความถูกต้องของอัลกอริทึมที่ทำการทดลองคือ ISVM และอัลกอริทึมของ SVM คอลัมน์แรกคือ 10 fold cross validation ของ MIAS คอลัมน์ที่สองและสี่คือความถูกต้องที่แยกได้ของ SVM และ ISVM โดยพิจารณาจาก 10 fold ส่วนคอลัมน์ที่สาม Attributes number คือจำนวนของการเลือกคุณลักษณะของ ISVM ที่ด้านล่างของ ตารางค่าเฉลี่ยของแต่ละคอลัมน์จะปรากฏขึ้น จากตารางสามารถสรุปได้ว่า ISVM นั้นมีประสิทธิภาพ ดีกว่าอัลกอริธึม SVM เพียงอย่างเดียวในแง่ของความถูกต้องในการจำแนกประเภท ที่เวลาเดียวกัน แต่ต้องแลกด้วยเวลาที่เพิ่มขึ้นในการทำ Reduction base on Importance function แต่เราจะได้ Attributes จริงๆ ที่มีผลต่อการจำแนกมากกว่าการใช้ SVM ร่วมกับ Attributes ทั้งหมดที่เราสามารถ Extract ออกมาได้จริง
อย่างไรก็ดี การทดสอบนี้นั้นใช้ข้อมูลจาก MIAS เท่านั้นเพื่อนำมาทดสอบจึงทำให้ประสิทธิภาพในการจำแนกสูงถึงกว่า 90% แต่ในโลกของความจริงใน real world นั้น เราไม่สามารถได้รูปที่สมบูรณ์แบบเพื่อมาทำ Features Extraction ได้อย่างมีประสิทธิภาพ เนื่องด้วยปัจจัยหลายอย่างที่ไม่สามารถควบคุมได้เช่น Technician ที่ทำงานที่เราไม่สามารถ control ในส่วน Quality ได้อย่างมีประสิทธิภาพ รวมถึงเครื่องไม้เครื่องมือต่างๆ ซึ่งมีผลต่อคุณภาพของ Image ที่จะนำมาทดสอบ แต่ก็เป็นการทดลองที่เห็นแนวโน้มของการใช้ AI หรือ Machine Learning มาใช้กับ Healthcare ซึ่งน่าจะมีบทบาทสำคัญต่อไปในอนาคตอันใกล้นี้อย่างแน่นอน
ติดตาม ด.ดล Blog เพิ่มเติมได้ที่
Fanpage : facebook.com/tharadhol.blog
Blockdit : blockdit.com/tharadhol.blog
Twitter : twitter.com/tharadhol
Instragram : instragram.com/tharadhol
References :

- https://www.bedfordbreastcenter.com/mammogram-los-angeles/
- http://ieeexplore.ieee.org/document/4731868/
- http://www.mammoimage.org/databases/
- https://link.springer.com/chapter/10.1007/978-3-540-73451-2_80
- http://ieeexplore.ieee.org/document/1040110/
- https://www.researchgate.net/publication/284700306_Medical_image_feature_extraction_selection_and_classification
- https://www.ncbi.nlm.nih.gov/pubmed/21611053
- http://elcvia.cvc.uab.es/article/view/216
Related Posts



ติดตามสาระดี ๆ อัพเดททุกวันผ่าน Line OA



Geek Forever Club พื้นที่ของการแลกเปลี่ยนข้อมูลข่าวสาร ความรู้ ด้านธุรกิจ เทคโนโลยีและวิทยาศาสตร์ ใหม่ ๆ ที่น่าสนใจ

Geek Forever’s Podcast
“Open Your World With Technology“
AI , Blockchain และเทคโนโลยีใหม่ ๆ กำลังเข้ามามีบทบาทสำคัญในหลายธุรกิจ ทั้ง แวดวงการเงิน สุขภาพ หรือ งานด้านบริการต่าง ๆ ผมเป็นคนหนึ่งที่สนใจเกี่ยวกับ AI หรือ Machine Learning
Podcast ของผมจะเล่าเรื่องราวต่าง รวมถึงเรื่องที่ผมสนใจอื่น ๆ เช่น startup หนังสือ หนัง หรือ กีฬาฟุตบอล อยากชวนคนที่สนใจให้ลองมาติดตาม podcast ของผมกันด้วยนะครับ