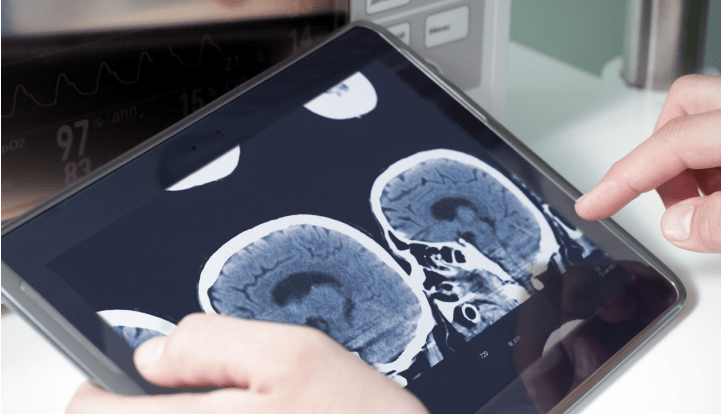
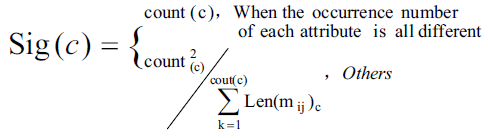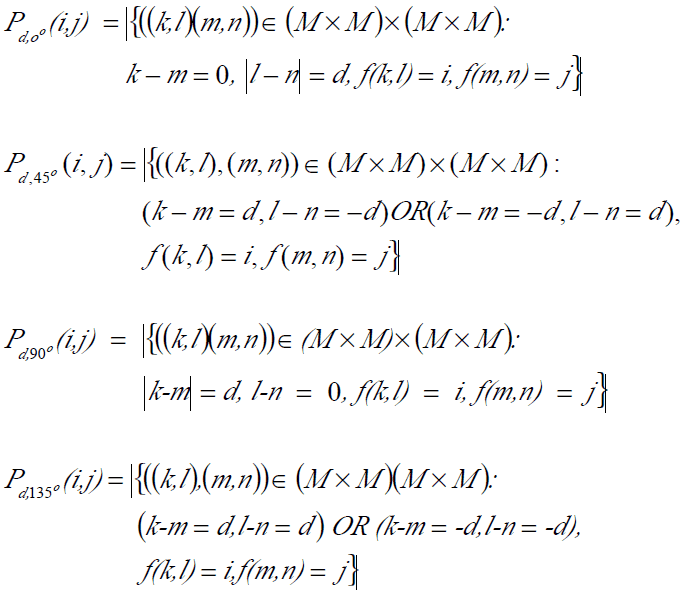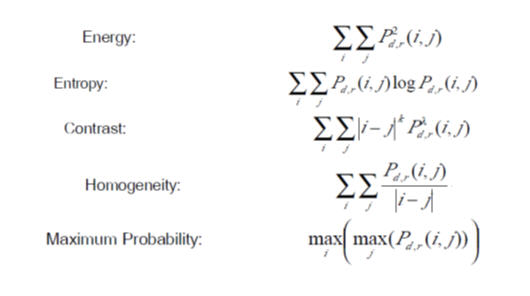จะเห็นได้ว่าปัจจุบันกระแสของ AI รวมถึง Machine Learning นั้นมาแรงมาก ซึ่งน่าจะกระทบกับชีวิตมนุษย์เราในอนาคตอันใกล้นี้ โดยส่วนนึงนั้นจะเข้าไปเกี่ยวข้องกับอุตสาหกรรมทางด้าน healthcare โดยตรง
จากข่าวก่อนหน้านี้ที่เราได้เห็น IBM ประกาศเข้าซื้อกิจการของ Merge Healthcare นั้น แสดงให้เห็นได้ว่าเทคโนโลยีของ AI เริ่มเข้าไปมีบทบาทโดยตรงกับธุรกิจ Healthcare อย่างแน่นอน ซึ่งการที่ IBM มี AI อย่างระบบ Watson ที่ใช้เวลา R&D มาอย่างยาวนานมากนั้น ก็ทำให้ประสิทธิภาพของมันสามารถพ้นขีดจำกัดบางอย่างของมนุษย์ที่จะสามารถทำได้ไปแล้วโดยเฉพาะวงการการแพทย์
และทำไม IBM ถึงได้ลงเงินมหาศาลเพื่อทำการ take over บริษัท Merge ที่เป็นบริษัททาง Healthcare ก็จริงแต่ เน้นไปทางงานด้าน Imaging หรืองานด้านรังสีแพทย์เป็นส่วนใหญ่ เช่นระบบ PACS หรือ ระบบ RIS ที่เกี่ยวข้องเชื่อมต่อกับงานทางด้านรังสี
IBM ซื้อ Merge Healthcare
ซึ่งมันต้องเกี่ยวข้องกับ Watson ที่บริษัทยักษ์ใหญ่อย่าง IBM ทำการ R&D มาอย่างยาวนานอย่างแน่นอน โดย IBM จะให้ Watson นำร่องเข้าสู่ธุรกิจ Healthcare ซึ่งเป็นธุรกิจที่มีมูลค่ามหาศาล ผ่านข้อมูลมหาศาลของ Merge Healthcare ซึ่งการเข้ามาสู่งานด้านรังสีนั้น เนื่องจากเป็นส่วนที่เน้นไปทางด้าน digital แบบเต็ม ๆ สามารถให้ AI มาช่วยเหลือเพื่อเป็น Decision Support System ให้กับแพทย์ได้
แต่ในปัจจุบันผู้ป่วยคนใดจะเชื่อมั่นใน AI มากกว่าหมอ? เช่นเดียวกันในอดีต เราก็ไม่เคยเชื่อว่า รถมันจะสามารถขับเองได้แบบอัตโนมัติ จน Tesla สามารถทำมันได้จริง ๆ จนผู้คนสามารถยอมรับได้ว่า AI สามารถขับรถได้ ซึ่งบางทีอาจจะขับได้ดีกว่ามนุษย์เราอีกด้วยซ้ำ เพราะผ่านการวิเคราะห์รวมถึงการคำนวณอย่างถี่ถ้วนมาแล้ว
Atrribute Reduction based on Atribute Importance Function
มี paper หลายตัวที่นำเสนอการใช้ Support Vector Machine ในการวิเคราะห์ มะเร็งเต้านม ซึ่งให้ค่าความแม่นยำไม่ต่างกันเท่าไหร่ในหลากหลายวิธี แต่ในตอนนั้นผมสนใจในเรื่องการ Improve Attribute base on Inportance Function ซึ่งเป็นการกรองคุณสมบัติ หรือ features ที่เป็นขยะออกไปให้มากที่สุด เนื่องจากเราใช้ค่าทางสถิติหลายอย่างในการจำแนก ซึ่งบางค่านั้นแทบจะไม่มีผลต่อความแม่นยำในการจำแนกผลเลยด้วยซ้ำ เทคนิค นี้ก็ทำเพื่อแยก คุณสมบัติที่มีผลต่อความแม่นยำจริง ๆ ให้ได้มากที่สุด ก่อนนำไป training
ซึ่งผมได้สนใจเป็นพิเศษในงานวิจัย An Improved Attribute Reduction Algorithm based on Attribute Importance function ได้นำเสนอวิธีในการลดคุณลักษณะของข้อมูลโดยปรับปรุงส่วนของ Discernibility Matrix ของ Attribute โดยจะพิจารณาจากฟังก์ชั่นที่สำคัญ เมื่อนำข้อมูลมาแปลงในรูปแบบของ Binary Discernibility Matrix รวมกับการคุณสมบัติการลดคุณลักษณะโดยใช้ Rough Set Theory โดยจะลดคุณลักษณะที่ไม่จำเป็นออกโดยใช้ฟังก์ชันสำคัญของคุณลักษณะที่ได้ทำการปรับปรุงผ่าน ของ Matrix ซึ่งจะสามารถทำให้มีประสิทธิภาพที่ดีขึ้น
โดยการพิสูจน์ทำโดยวิเคราะห์ความเปรียบต่าง (contrast) ซึ่งเมื่อมองใน time complexity นั้นจะมีประสิทธิภาพกว่างานวิจัยพื้นฐานของการใช้ Rough Set Theory ในการลดคุณลักษณะของข้อมูล วิธีการลดคุณลักษณะของ Matrix Binary Discernibility ซึ่งแม้ว่าคุณลักษณะที่ตรงกับคอลัมน์ใน Matrix ที่มีค่า “1” จำนวนมากนั้น ซึ่งในหลาย ๆ งานวิจัย แสดงให้เห็นว่าสามารถลดส่วนที่ไม่จำเป็นออกไปได้โดยมองจาก Importance Function ซึ่งมองที่ จำนวนการเกิดของคุณลักษณะ และ ความยาวขององค์ประกอบของ Discernibility Binary Matrix ซึ่งจะได้ค่าฟังก์ชั่นดังนี้
เมื่อ mij คือ Binary Discernibility Matrix ซึ่งได้จากการแปลงข้อมูลที่เราสนใจโดยใช้การDicretizationซึ่งจากสมการนั้น Count(c) หมายถึงจำนวนรวมของ c attribute ที่ปรากฏใน matrix Len c (mij) คือความยาวขององค์ประกอบใน matrix ที่มีคุณสมบัติ c
จากสมการจะได้ค่าตามอัตราส่วนของจำนวนลักษณะที่ปรากฏ และความยาวเฉลี่ยของ matrix ที่มีคุณสมบัติ c ซึ่งหมายความว่าถ้าการเกิดขึ้นของสองลักษณะที่แตกต่างกันจำนวนมาก ทำให้คุณลักษณะนั้นปรากฏมากขึ้น ซึ่งส่วนที่สำคัญในการลดคุณลักษณะคือ คุณสมบัติที่มีจำนวนการเกิดที่โดดเด่นของข้อมูลที่มีคุณลักษณะ c
ซึ่ง N หมายถึงจำนวน Gray Level ในภาพเต้านมโดย fk เป็นระดับสีเทา ที่ nk คือจำนวน pixel ที่ fk เป็น Gray Level และ n คือ จำนวน pixel ทั้งหมด
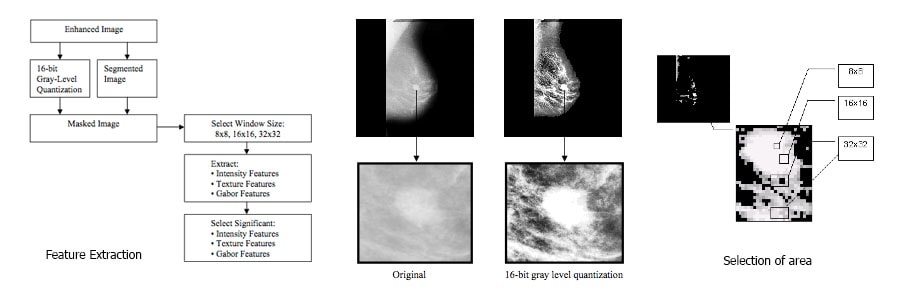
ซึ่งคุณสมบัติการจำแนกนั้นจะมีการคำนวณใน windows ที่มีขนาดเล็กของรูปต้นฉบับ โดยที่จะนำรูปต้นฉบับนั้นมาแบ่งเป็นสี่ส่วน เพื่อเพิ่มประสิทธิภาพในการจำแนกผล ซึ่งค่าสถิติต่าง ๆ ที่ได้ทำการคำนวณใน 16 ส่วนย่อยนั้น จะได้ค่าคุณสมบัติทั้งหมด 64 ค่าของแต่ละ image โดยจะนำค่าดังกล่าวไปประมวลผลกับเทคนิค Support Vector Machine เป็นลำดับต่อไป
Experiment
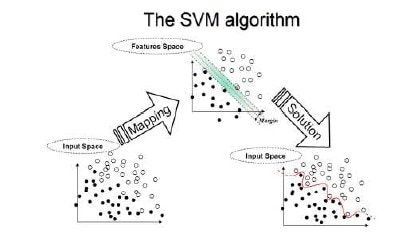
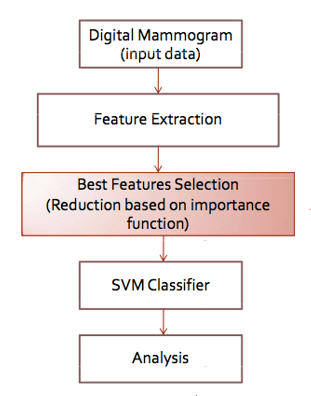
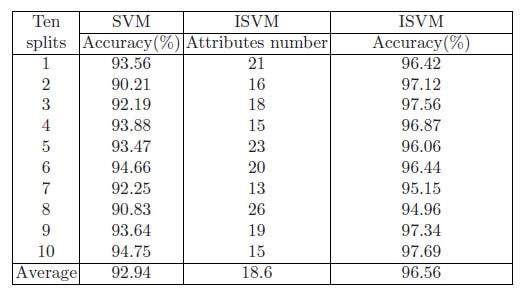
โดยในการทดลอง ก็จะนำเทคนิคและงานวิจัยที่เกี่ยวข้องดังกล่าวมาพัฒนาและปรับปรุง ในด้านประสิทธิภาพการทำงานทั้งในเรื่องของความแม่นยำของการจำแนก และรวมถึงประสิทธิภาพในการประมวลผลข้อมูลให้ดียิ่งขึ้น โดยการทดลองจะเน้นที่การปรับปรุงส่วนของการคัดเลือกคุณลักษณะที่เหมาะสม เพื่อให้ SVM algorithm ทำงานได้อย่างมีประสิทธิภาพมากขึ้น ซึ่งจากงานวิจัย ก่อนหน้านั้นจะเห็นได้ถึงแนวทางในการปรับปรุงการคัดเลือกคุณลักษณะที่เหมาะสมโดยมองที่ฟังก์ชั่นสำคัญ ซึ่งจะเป็นการลดคุณลักษณะของข้อมูล และเมื่อเปรียบเทียบกับการใช้ Rough Set Theory แบบ General Model หรือ การใช้ Genetic algorithm ร่วมกับเทคนิคของ Decision Tree นั้น ก็เป็นแนวทางที่สามารถทำให้ได้ผลการทดลองมีประสิทธิภาพมากยิ่งขึ้น
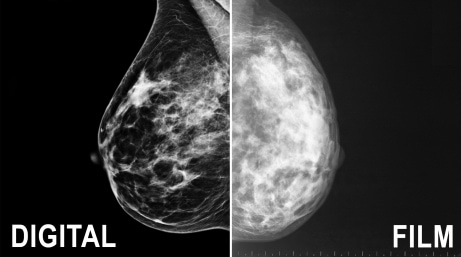
ซึ่งเมื่อทำการศึกษาจุดอ่อนและจุดแข็งของแต่ละงานวิจัยที่เกี่ยวข้องกับการจำแนกภาพดิจิตอลแมมโมแกรมนั้น เราสามารถใช้เทคนิค ที่มีอยู่มาปรับใช้ได้อย่างมีประสิทธิภาพ จึงเป็นจุดที่ผมสนใจที่จะนำเทคนิคต่าง ๆ ที่เกี่ยวข้องมาปรับและเพิ่มเติมในส่วนที่เป็นข้อบกพร่องกับการทดลองให้มีประสิทธิภาพการทำงานที่ดีขึ้น และสามารถใช้กับข้อมูลจริง ที่ได้จากการทำงานจริงกับโรงพยาบาลที่มีเครื่องมือประเภท Digital Mammogram เพื่อใช้ในการวิเคราะห์รักษาและช่วยจำแนกประเภทของข้อมูลภาพเต้านม ร่วมกับผู้เชี่ยวชาญที่เป็นแพทย์ทางด้านรังสีวิทยาได้อย่างมีประสิทธิภาพมากยิ่งขึ้น
ซึ่งจากงานวิจัยที่เกี่ยวข้องนั้นสามารถนำมาปรับปรุงการคัดเลือกคุณลักษณะเพื่อเพิ่มประสิทธิภาพโดยใช้เทคนิคของ Reduction Attribute based on important function เพื่อปรับปรุงความแม่นยำและประสิทธิภาพการทำงานของการคัดเลือกและจำแนกโดยใช้ SVM Algorithm กับภาพประเภทดิจิตอลแมมโมแกรมซึ่งมี วิธีการดังนี้
ส่วนของ input data นั้นผมจะใช้ภาพดิจิตอลแมมโมแกรมจาก MIAS ( Mammogram Image Analysis Society) ซึ่งเป็นข้อมูลที่ใช้เป็นมาตรฐานของงานวิจัยที่ยอมรับในปัจจุบันและจากงานวิจัยที่เกี่ยวข้องกับการทำ Feature Extraction ของดิจิตอลแมมโมแกรมนั้น จะใช้เทคนิคของ GLCM ในการ extract features ซึ่งจะได้ค่า features ที่มีประสิทธิภาพในการจำแนกผลที่ให้ความแม่นยำสูง
รวมถึงค่า features ทางด้านสถิติต่าง ๆ เพื่อเข้าสู่กระบวนการ Features Selection โดยใช้พื้นฐานของงานวิจัยในด้านการลดคุณลักษณะ ( Reduction Attribute based on important function) โดยจะมีการแก้ไขข้อจำกัดในเรื่องของ significant weight ที่จากงานวิจัยตัวอย่าง นั้นจะมีข้อจำกัดในข้อมูลที่ทำการ discretization ออกมาแล้ว Matrix เหลือขนาดเล็กเกินไปทำให้การคำนวณค่า significant weight