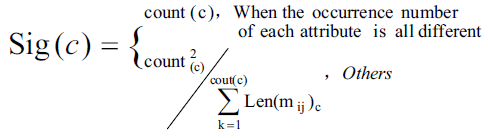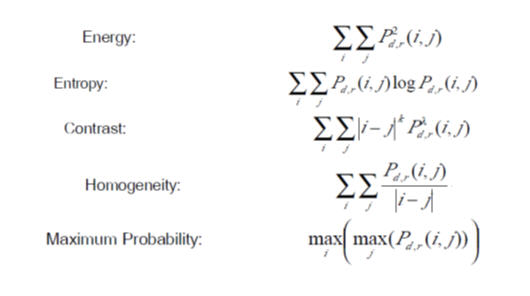ปัจจุบันนั้น เทคโนโลยีทางด้าน AI หรือ Machine Learning กำลังเป็นที่สนใจในหลาย ๆ ธุรกิจ ที่จะนำมาพัฒนาเครื่องมือต่าง ๆ เพื่อช่วยเหลือการดำรงชีวิตของมนุษยเราให้สะดวกมากยิ่งขึ้น ในแวดวงของการลงทุน AI ก็เริ่มเข้ามามีบทบาทมาช่วงหนึ่งแล้ว ซึ่งเราจะได้เห็นโฆษณาต่าง ๆ ผ่านหน้าผ่านตากันมาบ้าง ว่ามีกองทุนที่พัฒนาโดย AI มาคอยช่วยเหลือการ trade
งานวิจัยหลาย ๆ งานที่ได้ตีพิมพ์ในต่างประเทศนั้น ก็มีความน่าสนใจ ในแง่ของผลของการทดลองที่นำ AI มาช่วยประมวลผล และช่วยเหลือในการ trade ตัวอย่าง การวิเคราะห์ Market Trend ของหุ้น โดยใช้ปัจจัยพื้นฐานด้านข่าว ที่ผมเคยเขียน blog ไปก่อนหน้านี้ก็เป็นงานที่น่าสนใจ ที่นำปัจจัยเรื่องข่าวมาช่วยประมวลผล เพื่อทำการทำนาย market trend ที่กำลังจะเกิดกับหุ้นชื่อดังอย่าง AAPL ของ บริษัท apple ซึ่งผลนั้นก็ได้ความแม่นยำในระดับสูงกว่า 80% ซึ่งถือว่าเป็นผลที่น่าสนใจไม่ใช่น้อย
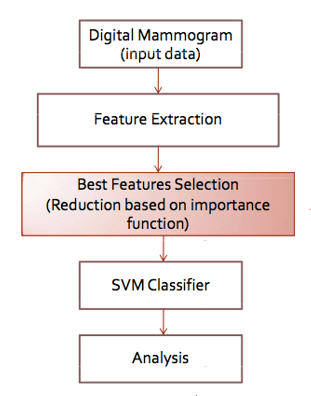
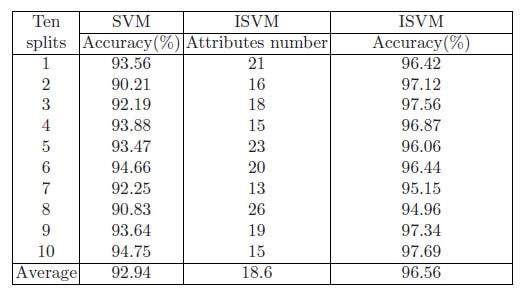
Support Vector Machine ก็เป็น algorithm หนึ่งที่น่าสนใจที่สามารถจำแนกและทำนายได้แม่นยำค่อนข้างสูงในหลาย ๆ case ตัวอย่างงานวิจัยที่ส่วนตัวเคยได้ทำ คือ Support Vector Machine กับการวิเคราะห์มะเร็งเต้านม ซึ่งเป็นการจำแนกมะเร็งเต้านมจาก Mammogram Image ได้ ซึ่งได้ความแม่นยำค่อนข้างสูงกว่า 90% แต่ปัจจัยหลักที่สำคัญสำหรับการจำแนกนั่นก็คือ Attribute หรือ Features ที่เป็นค่า input เพื่อให้ algorithm ทำการ train และ จำแนกนั้นก็เป็นปัจจัยสำคัญที่มีผลต่อความแม่นยำในการทำนายผล
ในวงการตลาดการเงิน หรือ commodity นั้นก็เริ่มมีการใช้โปรแกรมเข้ามาทำการช่วย trade มาเป็นเวลานานแล้ว ซึ่งจะเรียกว่า EA หรือ Expert Advisor ซึ่งมีหลายตัวที่น่าสนใจ และสามารถพัฒนาให้เทรดได้ดีกว่ามนุษย์ซึ่งในประเทศไทย ก็มีคนไทยได้พัฒนาอยู่มากมายในตลาด ด้วยการใช้ computer algorithm มาช่วยโดยผ่านการเขียนเงื่อนไขการทำงานแบบต่าง ๆ เพื่อทำตาม strategy การ trade ที่ตัวเองต้องการ ซึ่งสามารถใช้ภาษา mql4 ซึ่งเป็นภาษา Basic ที่สามารถเรียนรู้ได้ไม่ยาก และสามารถนำมาพัฒนา EA ได้ไม่ยาก
แต่ภาษา mql4 นั้นถูก design มาอย่างมีข้อจำกัดหลาย ๆ อย่าง ทำให้ไม่สามารถพัฒนาโปรแกรมที่ซับซ้อนได้มากเท่ากับ ภาษา mql5 ซึ่งเป็นภาษาที่ใหม่กว่า และมีการ design แบบลักษณะ Object-oriented programming สามารถที่จะเชื่อมต่อกับ interface ต่างๆ ข้างนอกได้ง่ายกว่าทั้ง device ต่าง ๆ รวมถึง network หรือ ระบบ cloud รวมถึง รองรับ timeframe ที่มากกว่า และสามารถพัฒนาโปรแกรมที่เข้าถึงเชิงลึกของ market ได้อย่างมีประสิทธิภาพมากกว่าภาษา mql4 โดยเฉพาะการทำงานด้าน AI ที่ใช้ Machine Learning ซึ่ง MT5 จะมี library มากกว่า
MT5 กับ ตลาดหุ้นไทย
โดยส่วนตัวก็คอยดูอยู่ว่า broker เจ้าไหนจะนำ MT5 มาใช้กับหุ้นไทยได้ซักที ซึ่งก็มีประกาศกันมานานแล้วเหมือนกัน โดยบอกว่าจะเริ่มใช้ได้กันตั้งแต่ปีที่แล้ว แต่ก็เลื่อนมาตลอด ซึ่งตอนนี้ก็มี applewealth ที่รองรับการใช้งาน MT5 และได้เปิดให้ trade จริงไปแล้วก่อนหน้านี้ แต่ที่โทรถามล่าสุดคือ ตอนนี้กลับมาปิดระบบอีกครั้ง ยังไม่มีกำหนดเปิดใหม่ แต่ส่วนของ demo นั้นเรายังสามารถนำมาทดสอบได้อยู่ ซึ่งผมก็จะมาแนะนำให้เตรียมตัวให้พร้อมสำหรับการสร้าง AI ด้วย algorithm Support Vector Machine เพื่อรอวันที่ตลาดหุ้นไทยเปิดให้ใช้อย่างเป็นทางการ

เข้า web site applewealth ส่วนของเครื่องมือการลงทุน->ทดลองใช้งานเพื่อ download MT5
ทำการ click Download : Installer MetaTrader 5 เพื่อทำการ download MT5 มา install ลงเครื่องคอมพิวเตอร์
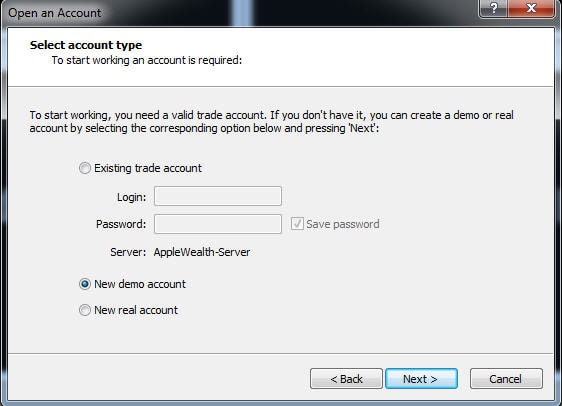
หลังจากนั้นก็ให้ทำการ install program ลงเครื่อง เมื่อ install เสร็จ ก็จะเข้าสู่ส่วนของการเลือก server ซึ่ง default ก็จะเป็น applewealth อยู่แล้ว ให้กด next และมาสู่ส่วนของการเลือก account ซึ่ง การทดสอบเราสามารถใช้ demo account ด้วยการเลือกที่ new demo account ได้
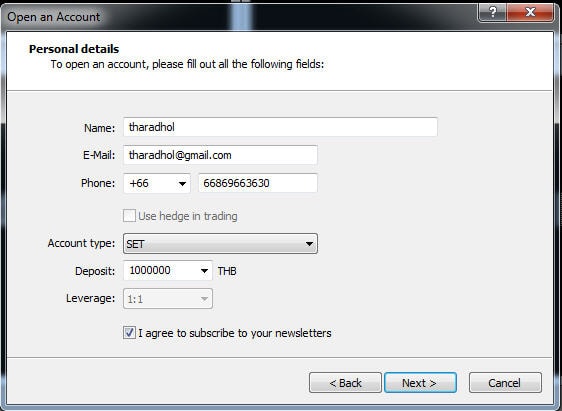
จากนั้นก็จะเข้าสู่ในส่วนของ Personal Details ซึ่งเราก็กรอกข้อมูลทั้งหมดเข้าไป account type ก็ทำการเลือก SET ส่วน Deposit นั้นคือเงินที่จะใช้ในการทดสอบ ซึ่งคล้าย ๆ demo ของ streaming pro ซึ่งหลาย ๆ ท่านน่าจะคุ้นชินกันอยู่แล้ว หลังจากนั้นให้ทำการกด next
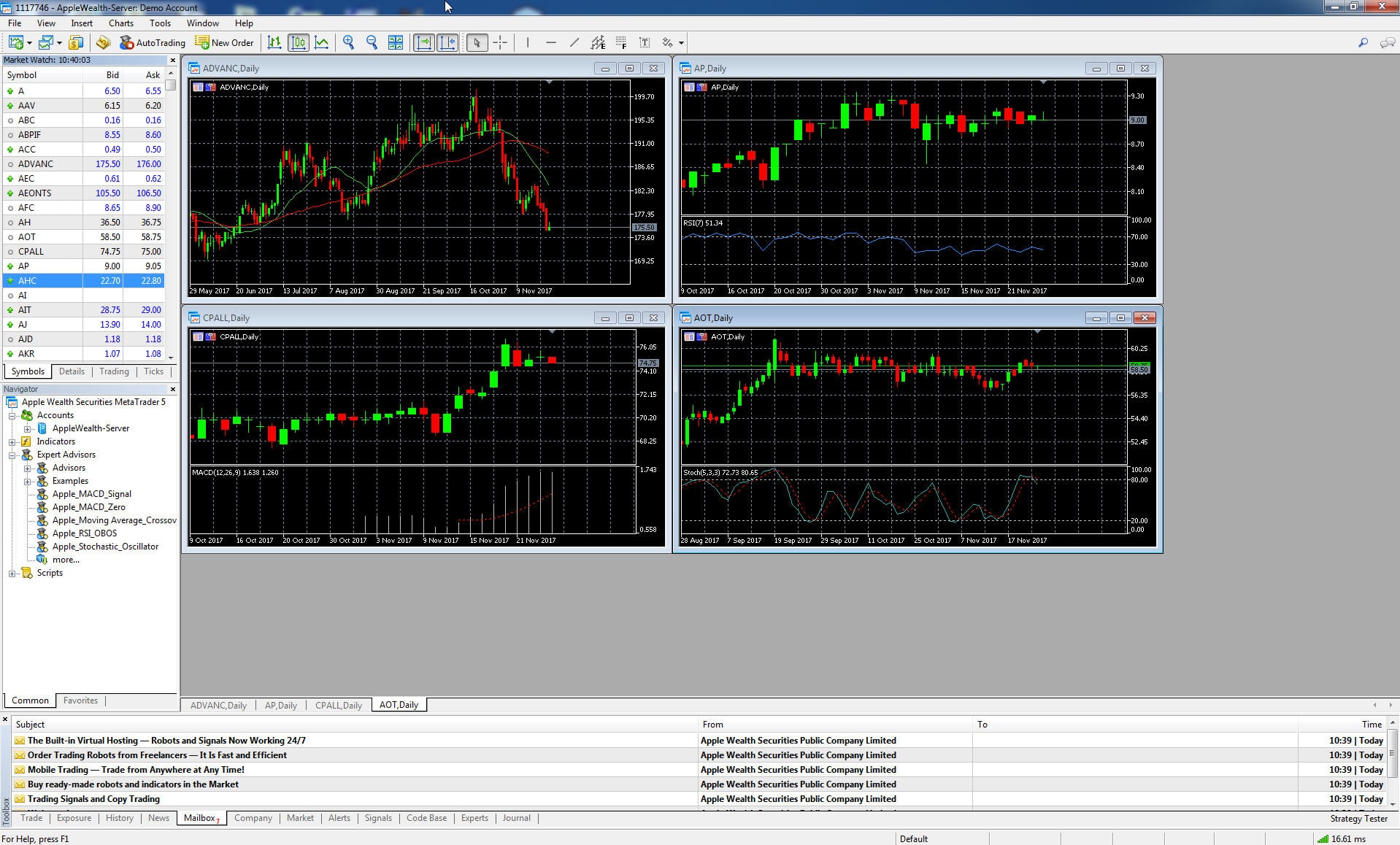
หลังจากเลือก new demo account เสร็จก็จะเข้าสู่หน้าจอ Main หลักของโปรแกรม ซึ่งจะประกอบด้วยส่วนต่าง ๆ ดังรูปข้างต้น ซึ่งจะประกอบไปด้วย ส่วนของ list รายการหุ้นไทยทั้งหมด ส่วนของ chart windows ซึ่งเราสามารถเลือกหุ้นที่ต้องการ monitor ได้ สามารถปรับ time frame รวมถึงรูปแบบของกราฟได้ และส่วนของ Navigator ซึ่งจะประกอบไปด้วย Indicators ต่าง ๆ รวมถึง Expert Advisors ซึ่งเป็นส่วนของ EA ที่จะใช้ในการ auto trade ซึ่งเราสามารถหา indicators รวมถึง EA ได้จาก Market ซึ่งมีให้เลือกใช้จำนวนมากมาย
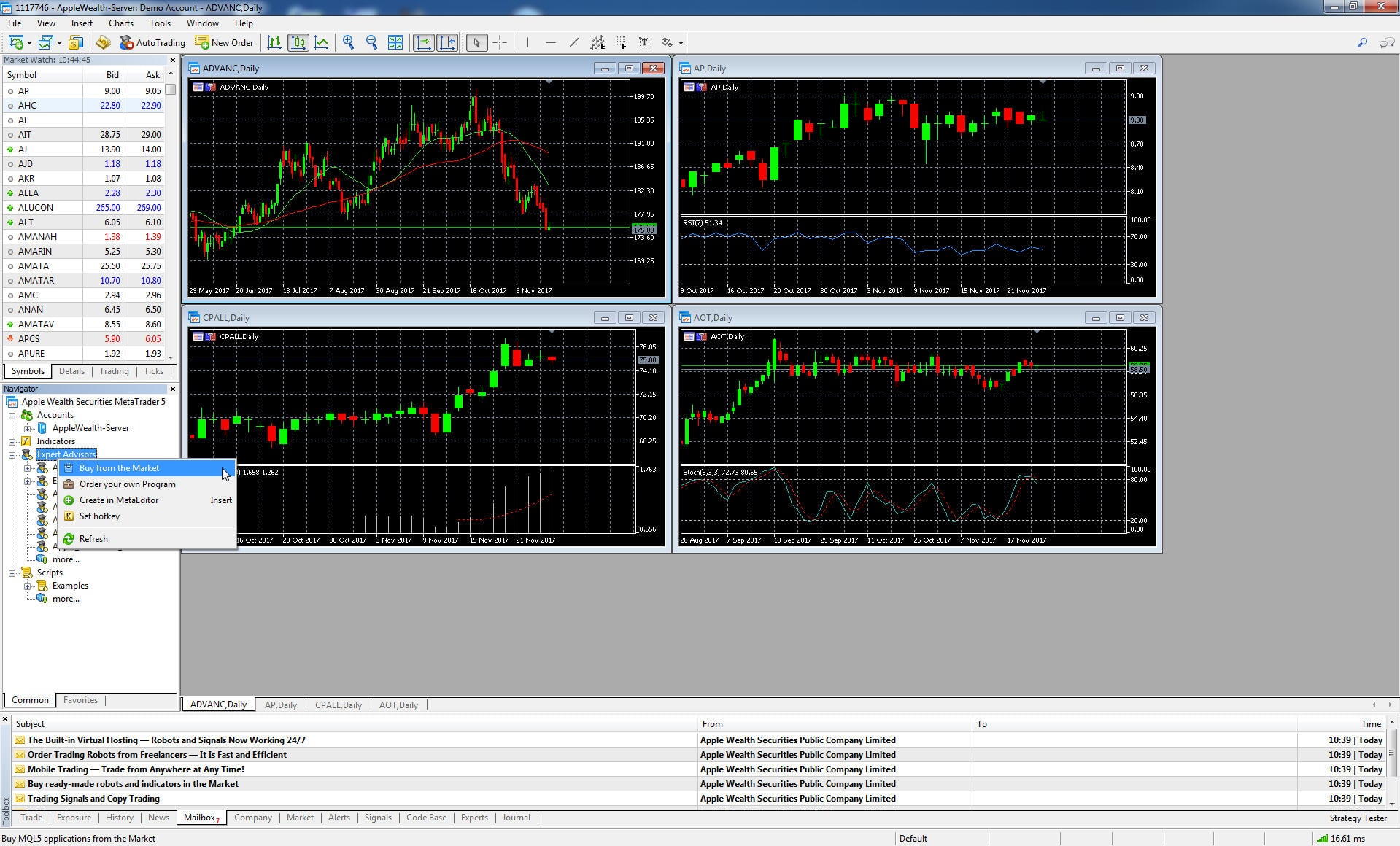
สำหรับ Support Vector Machine Library นั้นเราจะสามารถซื้อได้จาก Buy from the Market ซึ่งจะเป็น online market ที่มีการจำหน่าย หรือ แจก indicators หรือ EA ต่าง ๆ ที่น่าสนใจอยู่มากมายตาม startegy การ trade ของท่านซึ่งท่านสามารถเลือกได้ตามใจชอบ เราสามารถที่จะนำตัว demo version เพื่อมาทดสอบดูผลการ trade ผ่าน strategy tester ได้ ซึ่งส่วนนี้ผมจะ focus ในการใช้ Machine Learning Library ของ Support Vector Machine เป็นหลัก

ให้เราเข้าในส่วนการค้นหาและพิมพ์คำว่า svm เข้าไป ก็จะได้ผลการค้นหาเป็น Library ของ Support Vector Machine ซึ่งขายอยู่ที่ราคา 20 USD ซึ่งหากเราอยากทดลองใช้เราก็สามารถเลือกที่ demo เพื่อนำมาทดสอบก่อนได้ แต่เนื่องจากผมได้ซื้อมาเป็นที่เรียบร้อยแล้ว จึงสามารถนำมาเขียน code และนำไปใช้งานใน graph จริง ๆ ได้
จากรูปข้างบน นั้นจะแสดงรายละเอียดของ Library Support Vector Machine ซึ่ง เราสามารถกดที่ปุมสีเหลืองด้านขวาบน เพื่อนำตัว demo มาทำการทดสอบผ่าน Strategy Tester ได้ แต่จะไม่สามารถนำไปใช้ทดลองใน graph จริง ๆ ได้

สำหรับการใช้งาน EA ตัวอย่างสำหรับการใช้งาน Support Vector Machine นั้นผมได้ทำการสร้างตัวอย่างไว้ให้สามารถ download ได้จาก svm_thai_stock ซึ่งประกอบด้วย 2 file คือ svm_thai_stock.ex5 และ svm_thai_stock.mq5 โดยสามารถ copy ไปยัง folder ของ Data Folder ซึ่งสามารถดูได้จากรูปด้านบน หรือเข้า menu File-> Open Data Folder และทำการ copy ทั้ง 2 file ไปยัง \MQL5\Experts ซึ่งจะเป็น folder ที่ใช้เก็บ EA ทั้งหมดเพื่อนำมาใช้งาน
Support Vector Machine คืออะไร
Support Vector Machine เป็นตัวแบบที่ใช้ในการระบุตัวบุคคลหรือ object โดย SVM จะทำการแบ่งชั้นของข้อมูลด้วยระนาบหลายมิติ จากข้อมูล 2 กลุ่มชุดข้อมูล โดยตัวแบบของ SVM เกี่ยวข้องกับเครือข่ายประสาทเทียม ซึ่งโดยอันที่จริงแล้วตัวแบบของ SVM ใช้ Sigmoid Kernel Function ซึ่งมีค่าเท่ากันทั้ง 2 เลเยอร์เป็นตัวแบบที่ใช้ในการระบุตัวบุคคล โดย SVM จะทำการแบ่งชั้นของข้อมูลด้วยระนาบหลายมิติ จากข้อมูล 2 กลุ่มชุดข้อมูล โดยตัวแบบของ SVM เกี่ยวข้องกับเครือข่ายประสาทเทียม
ซึ่งโดยอันที่จริงแล้วตัวแบบของ SVM ใช้ Sigmoid Kernel Function ซึ่งมีค่าเท่ากันทั้ง 2 เลเยอร์ ตัวแบบของ SVM มีความคล้ายคลึงกับเพอร์เซฟตรอนซึ่งเป็นข่ายงานประสาทเทียมแบบง่ายมีหน่วยเดียวที่จำลองลักษณะของเซลล์ประสาท ด้วยการใช้ Kernal Function
โดยใน paper ที่ตีพิมพ์เกี่ยวกับ SVM นั้นจะเรียกตัวแปรในการตัดสินใจว่า คุณสมบัติและตัวแปรที่เปลี่ยนแปลงใช้ในการกำหนดระนาบหลายมิติ ซึ่งเรียกว่า โครงสร้าง (feature) ส่วนการเลือกที่มีความเหมาะสมที่สุดเรียกว่า โครงสร้างในการคัดเลือก (feature selection) จำนวนเซตของโครงสร้างที่ใช้อธิบายในกรณีหนึ่ง (เช่น แถวของการค่าที่เราคาดการณ์) เรียกว่า เวกเตอร์ (vector) ดังนั้นจุดมุ่งหมายของตัวแบบ SVM คือการประโยชน์สูงสุดจากระนาบหลายมิติที่แบ่งแยกกลุ่มของเวกเตอร์ในกรณีนี้ด้วยหนึ่งกลุ่มของตัวแปรเป้าหมายที่อยู่ข้างหนึ่งของระนาบ และกรณีของกลุ่มอื่นที่อยู่ทางระนาบต่างกัน ซึ่งเวกเตอร์ที่อยู่ข้างระนาบหลายมิติทั้งหมดนี้เราจะเรียกว่า ซัพพอร์ตเวกเตอร์ (Support Vectors)
เราใช้ Support Vector Machine ในตลาดหุ้นอย่างไร

การวิเคราะห์ทางด้านเทคนิคนั้นอยู่บนพื้นฐานของการใช้ข้อมูลที่ผ่านมาเพื่อคาดการณ์การเคลื่อนไหวของราคาในอนาคต อย่างไรก็ดี ตลาดหุ้นนั้นมีความผันผวนมาก และ การใช้เพียงแค่ indicator อย่างเดียวนั้นอาจจะเกิดข้อผิดพลาดทางด้านสถิติได้ ซึ่งการนำ Machine Learning มาใช้งานร่วมกับ indicators ต่าง ๆ เหล่านี้นั้นทำให้เพิ่มในส่วนของการ training data เพื่อให้ SVM ได้ทำการเรียนรู้ และ ประเมินความแม่นยำของการเข้า trade ซึ่งการประเมินในเรื่องความแม่นยำในการ trade ผ่านการ training ก่อนนั้น ทำให้เราสามารถวิเคราะห์ได้ว่า ควรเข้า trade ใน strategy นั้น ๆ หรือไม่
สำหรับ process การทำงานของ SVM Library มีดังนี้

วิธีการ Generated Training Inputs
สำหรับตัว indicators หรือค่า Features ที่เราต้องการนำมาใช้เป็น input นั้น ใช้วิธีการ initial ค่าจาก period ที่คุณต้องการ

จากตัวอย่าง code แสดงค่า indicators iBearsPower , iBullsPower , iATR , iMomentum , iMACD , iStochastic , iForce สำหรับเป็น input ที่ใช้ในการ training โดยจะใช้ function ตามตัวอย่าง code คือ genInputs(handleB) สำหรับการ generate ค่าตั้งต้นของ indicators ต่าง ๆ ที่เราสนใจ
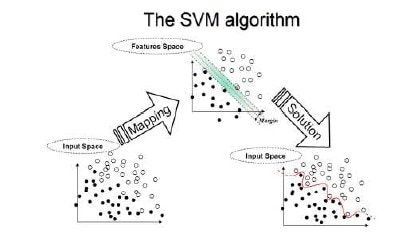
สำหรับค่า offset และ ค่า N_Datapoints นั้นจะแสดงตามตัวอย่างรูปข้างบน โดยจะพิจารณาตามแทงเทียนของ timeframe นั้น ๆ เช่น Offset = 4 คือ เราใช้ input ก่อนหน้าแท่งเทียนปัจจุบัน จำนวน 4 แท่งเทียน ส่วน N_Datapoints ตามตัวอย่างในรูป = 6 เราจะนำค่าจากแท่งเทียนอีก 6 แท่งเทียนก่อนหน้าค่า offset ไปทำการ generate input ซึ่งจำนวน N_Datapoints นั้นยิ่งมากก็จะใช้เวลาในการ training เพิ่มมากขึ้นไปด้วย ซึ่งจะมีผลต่อความแม่นยำหรือไม่นั้น ก็อาจจะตอบได้ทั้งสองคำตอบ คือ มี หรือ ไม่มีเลยก็ได้ ซึ่งเราต้องหาค่า N_Datapoints ที่เหมาะสมที่สุดสำหรับการ training เพื่อให้ความแม่นยำเกิดขึ้นสูงสุด
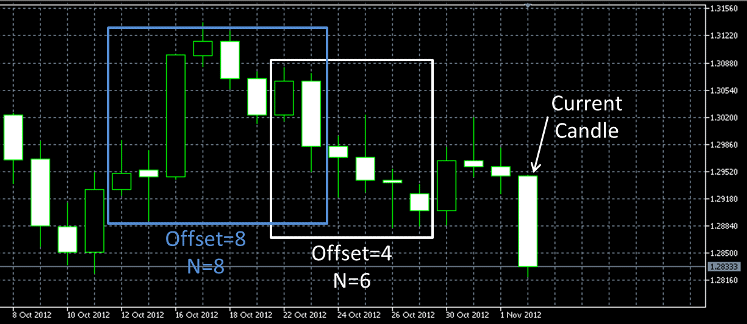
สำหรับส่วนของ onbar function นั้น คือ เมื่อเกิดแท่งเทียนใหม่ตาม timeframe ระบบก็จำค่า indicator ณ เวลานั้น ๆ มาทำการ classify หาว่าควรที่จะเข้าทำการซื้อหุ้น ณ ขณะนั้นหรือไม่ หาก Opn_B = true คือ ระบบ predict ให้ซื้อ
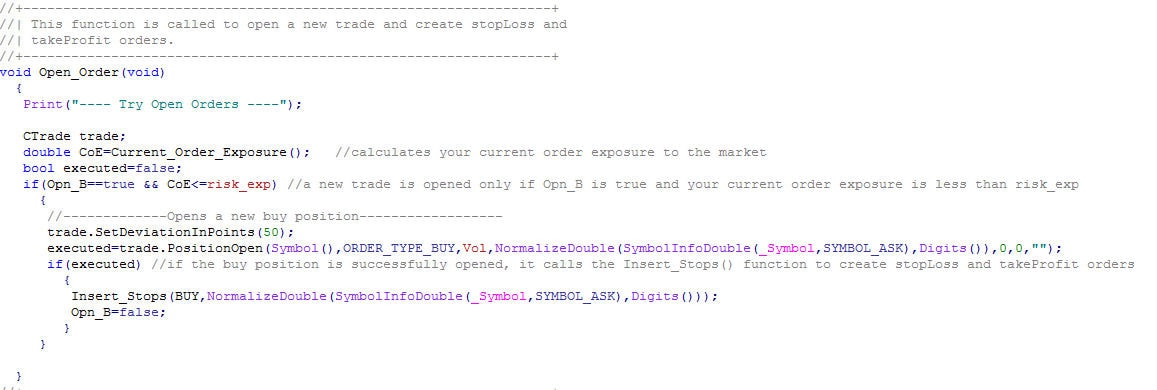
จาก onbar function หากระบบได้รับสัญญาณการเข้าซื้อก็จะเข้าสู่ function Open_Order เพื่อทำการซื้อผ่าน mt5 โดย Vol ก็คือจำนวนเงินที่จะใช้ในการเข้าซื้อ ซึ่งเราสามารถ set ในส่วนของ input data
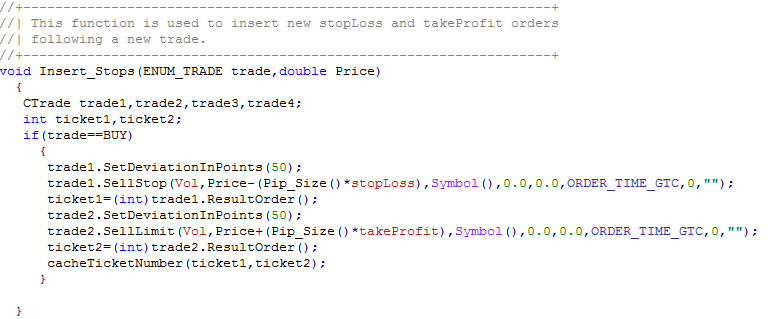
สำหรับส่วนของ Insert_Stops นั้น เป็นการกำหนดจุด stopLoss และ จุดที่เราจะ takeProfit ซึ่ง จะมีหน่วยเป็น Pips ซึ่งจะใช้กันในการ trade พวก currency หรือ commodity ซึ่งในหุ้นไทยนั้น ส่วนใหญ่จะหมายถึงการเคลื่อนของราคาที่ 0.01 ซึ่งหากเรา set ค่า takeProfit ไว้ที่ 100 pips คือ 0.01 * 100 = 1 ก็คือระบบจะปิดที่ ราคาปัจจุบัน + 1 บาท ถือเป็นจุด tp ของระบบ เช่นเดียวกับการ stoploss ก็ใช้หลักการเดียวกัน
ผลการทดสอบ
ผมได้ทำการทดสอบกับหุ้นไทยจำนวน 4 ตัวประกอบด้วย BDMS , BEAUTY , BH และ BMCL ด้วย timeframe 15m โดยใช้ offset ที่ 0 และ N_DataPoints = 100 จุด takeprofit ที่ 100 pip และ stoploss ที่ 150 pip ด้วย indicators พื้นฐานตามที่ได้กล่าวข้างต้น ได้ผลการทดสอบดังนี้
1.BDMS
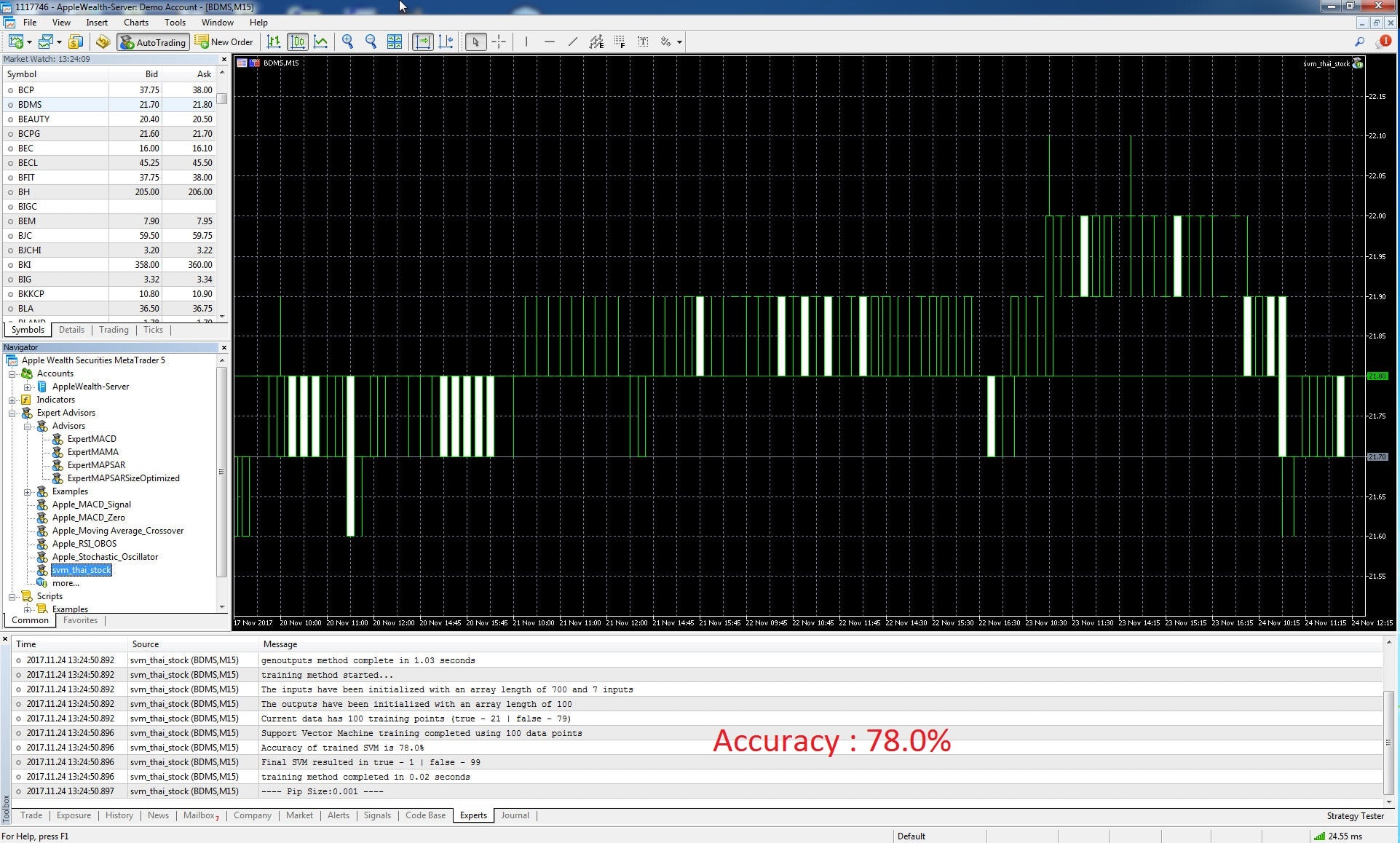
จากการ training นั้นได้ผลความแม่นยำที่ 78.0%
2.ฺBEAUTY
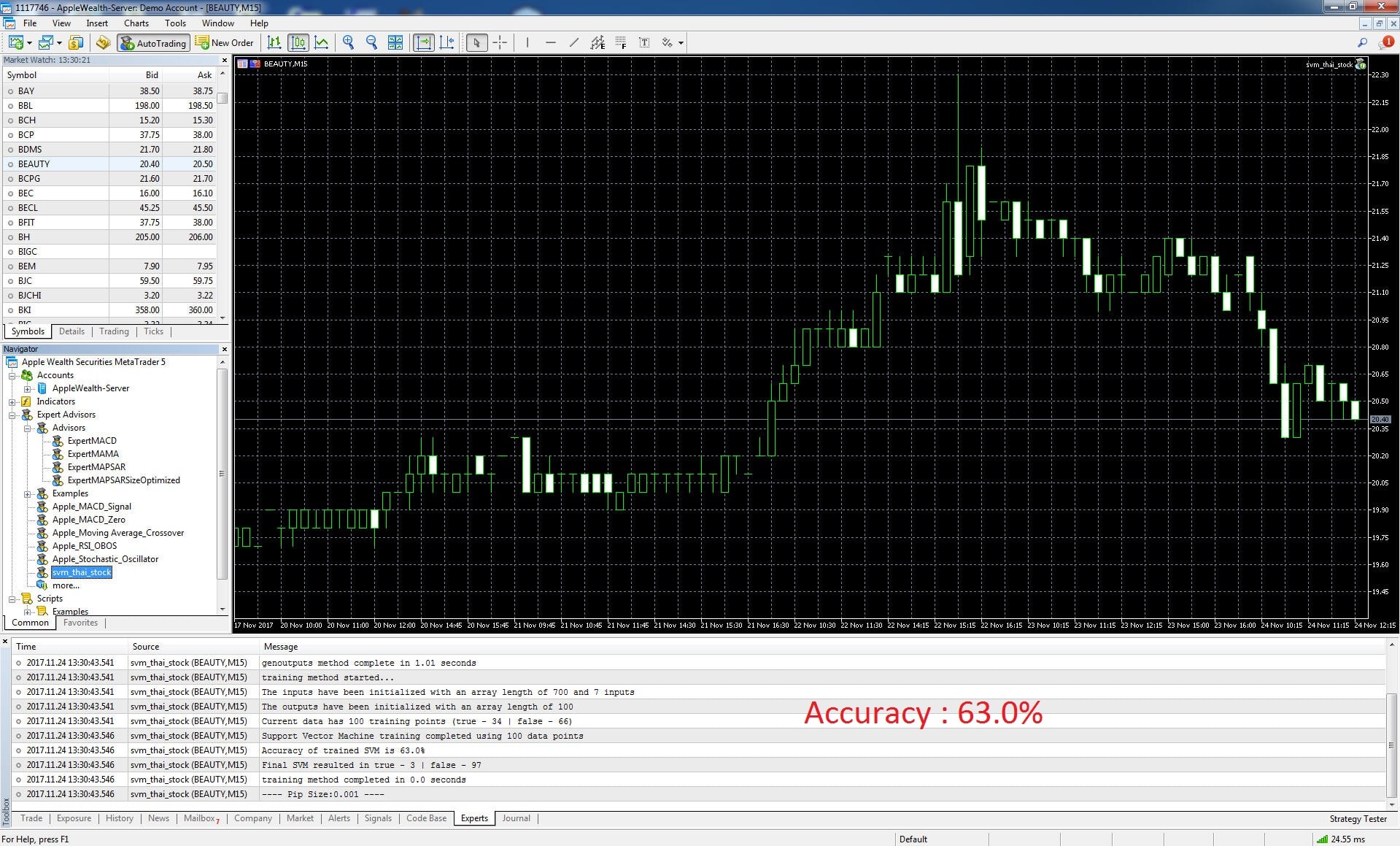
จากการ training ได้ผลความแม่นยำที่ 63.0%
3.ฺBMCL
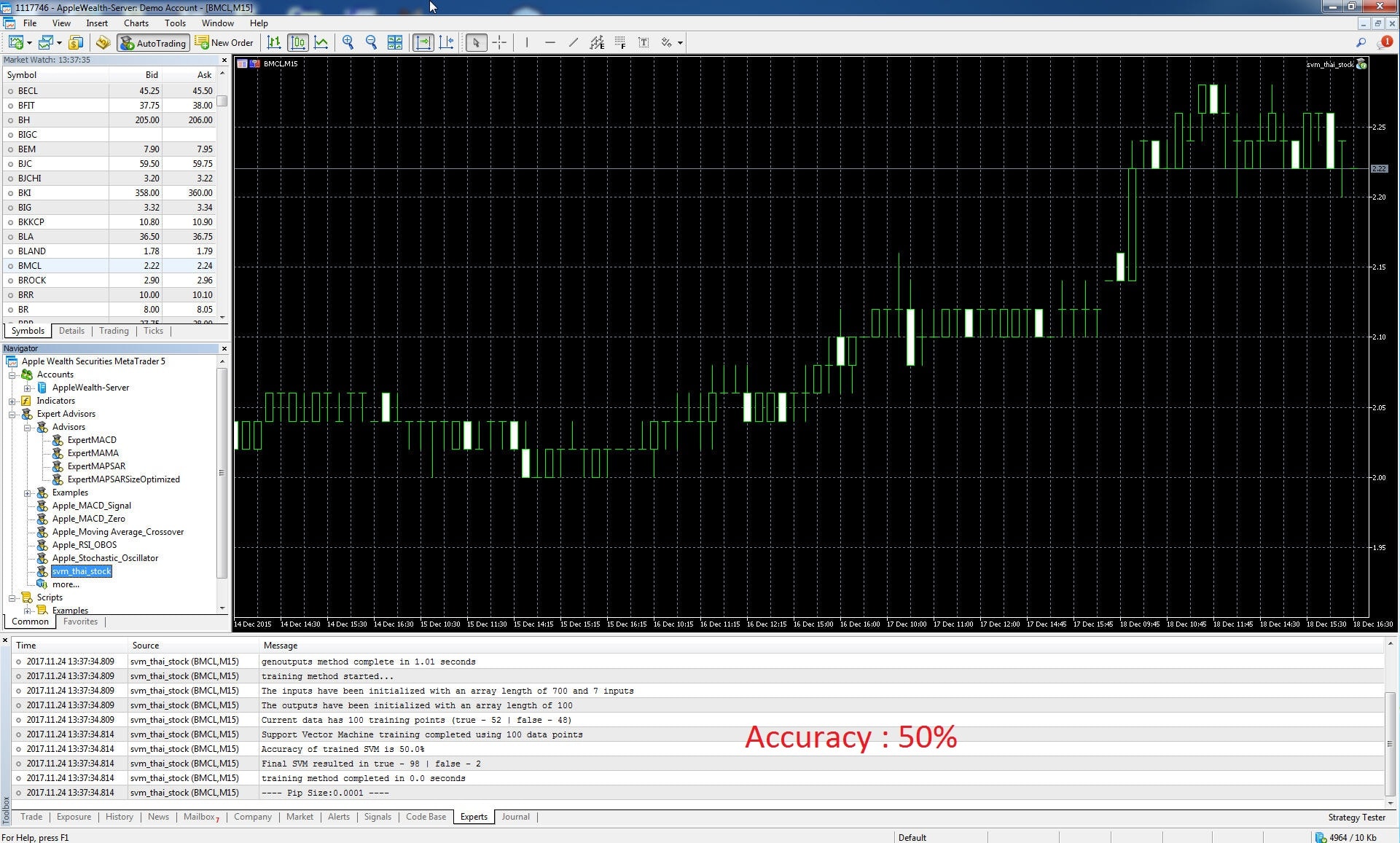
จากการ training ได้ผลความแม่นยำที่ 50% ซึ่งถือว่าเทียบเท่าการโยนเหรียญ หัว-ก้อย
4.ฺBH

ถือว่าน่า surprise สำหรับ BH ที่ได้ค่าความแม่นยำจากการ training สูงถึง 87%
สรุป
จาก blog นี้นั้นเป็นการ guide ให้เห็นถึงแนวทางสำหรับการพัฒนา AI ที่ใช้ Machine Learning จริง ๆ เพื่อใช้ทดสอบความแม่นยำในการ prediction market trend ที่จะเกิดในอนาคต ซึ่ง จากตัวอย่างนั้นผมใช้เพียง indicators พื้นฐานเท่านั้นในการทดสอบความแม่นยำของ Support Vector Machine ซึ่งผลในหุ้นบางตัวอย่าง BH นั้นก็ถือว่าน่าสนใจไม่ใช่น้อยสำหรับควาแม่นยำที่สูงถึงระดับ 87% ซึ่ง ผมคิดว่าส่วนนี้เป็นแนวทางที่จะนำไปใช้พัฒนาต่อ สำหรับนักเทรดสายเทคนิคอล ที่มี strategy ที่ตัวเองนั้นถนัดอยู่แล้ว น่าจะลองมาใช้ machine learning เพื่อเพิ่มประสิทธิภาพในการ trade ดู ซึ่งผมคิดว่าน่าจะได้ผลที่ดีขึ้น
ซึ่งในส่วนของ Library ของ Support Vector Machine ใน MT5 นั้น ก็ได้ทำการปรับมาเพื่อใช้กับการ trade โดยเฉพาะ ทำให้สามารถใช้งานได้อย่างไม่ยาก แต่เราอาจจะ customise ได้ดั่งใจเราไม่มากเท่าที่ควร แต่หากต้องการการทำงานในระดับ Advance นั้นผมก็แนะนำให้ใช้เทคนิค การ call LIBSVM โดยอาจจะเรียกผ่าน Web Service หรือ http protocol ซึ่งเราอาจจะสามารถ customise ได้มากกว่า และอาจจะให้ผลความแม่นยำที่สูงกว่า เหมือนงานวิจัยหลาย ๆ ชิ้นที่ผ่านมา
ส่วนค่า features หรือ input นั้น เราอาจจะไม่ได้ใช่แค่ indicators มาตรฐานมาใช้ในการ train เท่านั้น เราอาจจะสามารถกำหนด features ที่ต้องการเอง ตาม Strategy การเทรดของเรา ซึ่งคิดว่าหลาย ๆ ท่านนั้นก็น่าจะมี strategy การเทรดที่แตกต่างกัน หรือมีการพลิกแพลงค่าต่าง ๆ เช่นเส้น trend line หรือ เส้นแนวรับ แนวต้าน ก็เป็นสิ่งที่สามารถนำมาเป็น input ได้ ส่วนเรื่องข่าวก็เป็นสิ่งที่น่าสนใจที่จะสามารถนำมาใช้เป็น features ได้ ดังตัวอย่าง การวิเคราะห์ Market Trend ของหุ้น โดยใช้ปัจจัยพื้นฐานด้านข่าว ซึ่งผมคิดว่า AI ที่ใช้ Machine Learning นั้นจะมีบทบาทต่อวงการเทรดหุ้นของประเทศไทยอย่างแน่นอน อย่างที่หลาย ๆ บริษัทได้เริ่มพัฒนา AI ที่ใช้ในการ trade แล้ว ซึ่งต่อไปนั้น เราอาจจะไม่ได้แข่งกับแค่ ต่างชาติ หรือ นักลงทุนสถาบันเท่านั้น เหล่าเม่าตัวน้อย ๆ อย่างพวกเรา อาจจะต้องสู้รบปรบมือกับกองทัพ AI ในเร็ววันนี้ก็เป็นไปได้
References : www.mql5.com,www.dailynews.co.th
ติดตาม ด.ดล Blog เพิ่มเติมได้ที่
Fanpage : facebook.com/tharadhol.blog
Blockdit : blockdit.com/tharadhol.blog
Twitter : twitter.com/tharadhol
Instragram : instragram.com/tharadhol