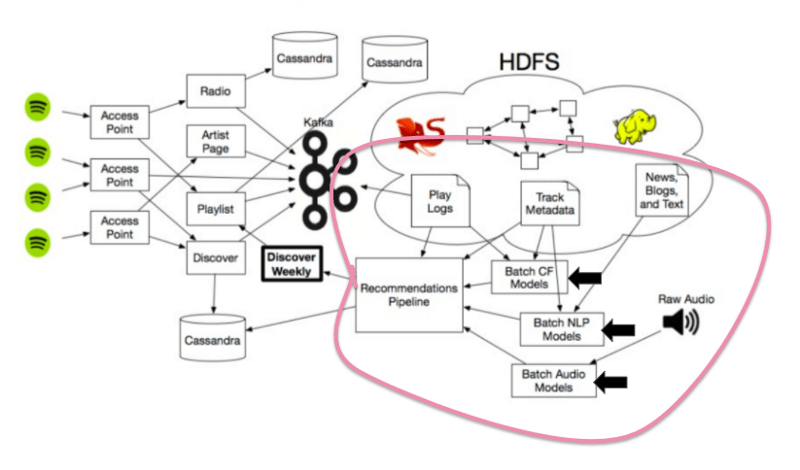
ซึ่ง Python Library นั้นจะ run matrix ทั้งหมดโดยใช้สมการคือ
สมการ python
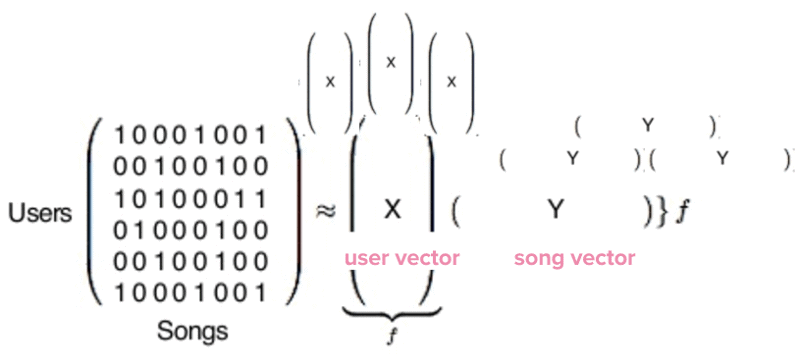
ซึ่งเมื่อ run จบนั้น จะได้รูปแบบของ Vectors สองชนิดคือ X จะแทน user vector ซึ่งจะหมายถึง รสนิยมการฟังเพลงของ single นั้น ๆ ของ user ส่วน Y นั้นจะเป็น song vector จะเป็นตัวแทนของ profile ของเพลงนั้น ๆ
The User/Song matrix produces two types of vectors: User vectors and Song vectors
ซึ่งเราจะได้ User Vectors จำนวน 140 ล้านตามจำนวน user ทั้งหมดในระบบ และ Song Vectors จำนวน 30 ล้าน ตามจำนวนเพลงทั้งหมดในระบบ ซึ่งเหล่า Vector ข้อมูลเหล่านี้นั้น เป็นประโยชน์อย่างยิ่งในการเปรียบเทียบรสนิยมการฟังเพลงของ user แต่ละคน ซึ่งการที่จะหาว่า user คนใด ๆ มีรสนิยมการฟังเพลงคล้ายกับใครนั้น จะต้องใช้ collaborative filtering ในการเปรียบเทียบ vector ของ user นั้น ๆ กับ vector ของคนอื่น ๆ ในระบบทั้งหมด ซึ่งเมื่อใช้ computer algorithm ทำการเปรียบเทียบทั้งหมด เราก็จะได้เห็นว่าใครมีรสนิยมการฟังเพลงคล้ายกัน เช่นเดียวกับในส่วนของ Song Vector เราก็ต้องนำ song vector ของเพลงนั้น ๆ ไปเปรียบเทียบหาจาก song vector ของเพลงทั้งหมดในระบบ ก็จะได้เพลงที่มีสไตล์คล้าย ๆ กัน ถึงแม้ว่าจากตัวอย่างที่ผ่านมานั้น collaborative filtering นั้นสามารถที่จะให้ผลลัพธ์ที่น่าสนใจ แต่ spotify ก็รู้ว่าเค้าต้องทำอะไรได้ดีกว่าการใช้ engine รูปแบบเดียวกับบริการอื่น ๆ เพียงอย่างเดียว
Recommendation Model #2 : Natural Language Processing (NLP)
สำหรับส่วนที่ 2 ใน Recommendation Model ของ Spotify นั้นใช้ เทคนิค ของ Natural Language Processing (NLP) สำหรับ source ของข้อมูลที่จะนำมา analyse ผ่านเทคนิค NLP นั้นจะใช้ ข้อมูลของ track metadata ของเพลง , news articles, blogs รวมถึงข้อมูลที่เป็น text อื่น ๆ ในระบบ internet
Natural Language Processing (NLP)
Natural Language Processing นั้น จะเป็นการใช้ความสามารถของ computer ในการวิเคราะห์ข้อความ text โดยส่วนใหญ่นั้นจะใช้วิธีผ่าน sentiment analysis APIs ซึ่งผมได้เคยเขียน blog การวิเคราะห์ Market Trend ของหุ้น โดยใช้ปัจจัยพื้นฐานด้านข่าวซึ่งจะใช้เทคนิคคล้าย ๆ กันคือ sentiment analysis เพื่อไปวิเคราะห์ market trend ของหุ้น
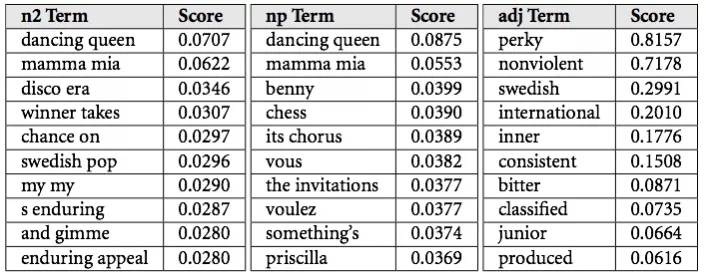
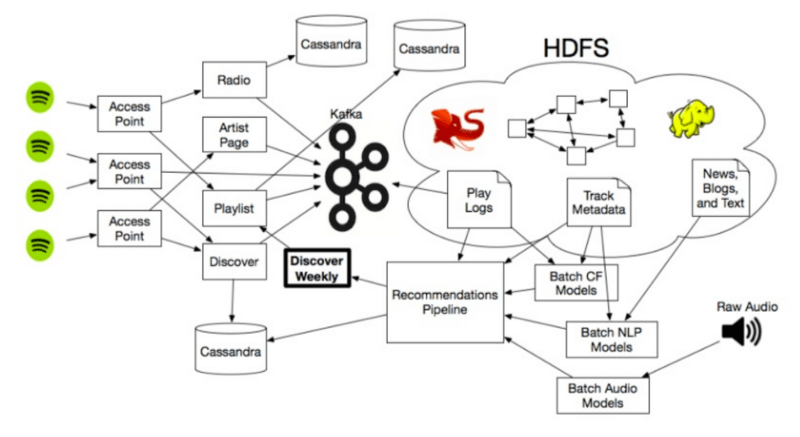
โดยรูปแบบการทำงานเบื้องหลังของ NLP ที่ spotify ใช้นั้น spotify จะสร้าง crawls คล้าย ๆ กับที่ google ใช้ในการเก็บ index ข้อมูล data เพื่อมา index ให้ user ทำการค้นหา แต่ spotify นั้นจะ focus ไปที่ blogs หรือ งานเขียน ที่เกี่ยวข้องกับวงการเพลง และนำมาวิเคราะห์ว่าผู้คน ใน internet กำลังพูดถึง ศิลปิน หรือ เพลงนั้นๆ อย่างไร แต่วิธีการในการ process ข้อมูลเหล่านี้นั้นยังเป็นความลับที่ spotify ยังไม่มีการเผยแพร่ออกมาว่าจัดการกับข้อมูลเหล่านี้อย่างไร แต่จะขอยกตัวอย่างจาก Echo Nest ที่ใช้วิธีการคล้าย ๆ กัน ซึ่ง Echo Nest นั้้นนำข้อมูลมา process โดยเรียกว่า “cultural vectors” หรือ “top terms” โดยแต่ละ ศิลปิน รวมถึง แต่ละเพลงนั้น จะมีการเปลี่ยนแปลงของ top-terms อยู่ทุกวันผ่านการ analysis ข้อมูลจากระบบ internet ซึ่งแต่ละ term นั้นจะมีค่า weight อยู่ ขึ้นอยู่กับความสำคัญของคุณลักษณะของแต่ละ term
“Cultural vectors” , or “top terms” , as used by the Echo Nest.
หลังจากนั้น รูปแบบก็จะคล้าย ๆ กับ collaborative filtering ซึ่ง NLP Model จะใช้ terms และ weights ในการสร้าง vector ของเพลง ซึ่งสามารถที่จะนำมาเปรียบเทียบว่า เพลงใด มีสไตล์ คล้าย ๆ กับเพลงใด ซึ่งจะส่งผลต่อการแนะนำให้กับ user ที่ใช้งานได้ตรงรสนิยมของ user คนนั้น ๆ ได้
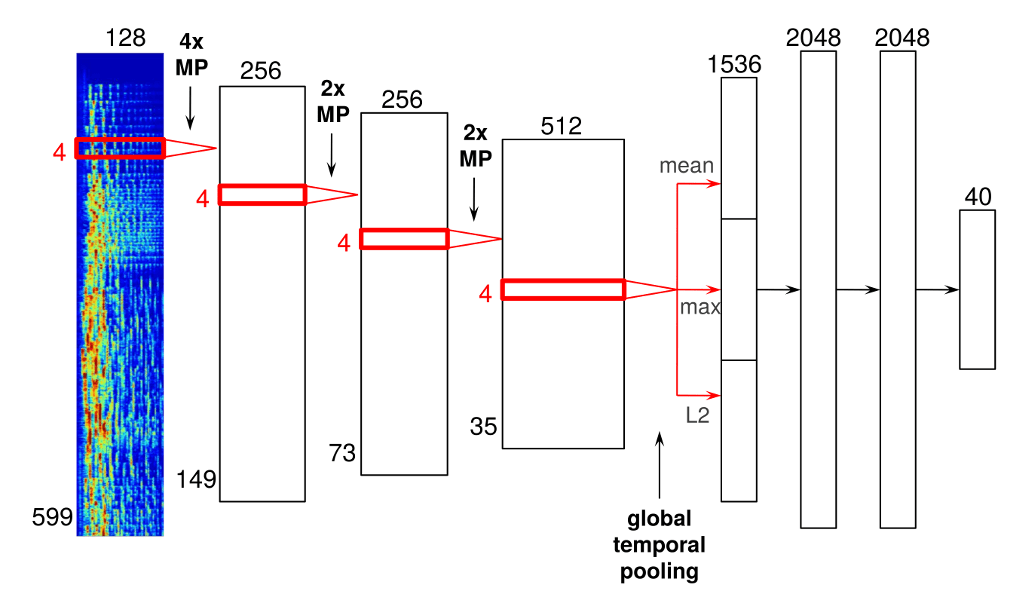
Recommendation Model #3: Raw Audio Models
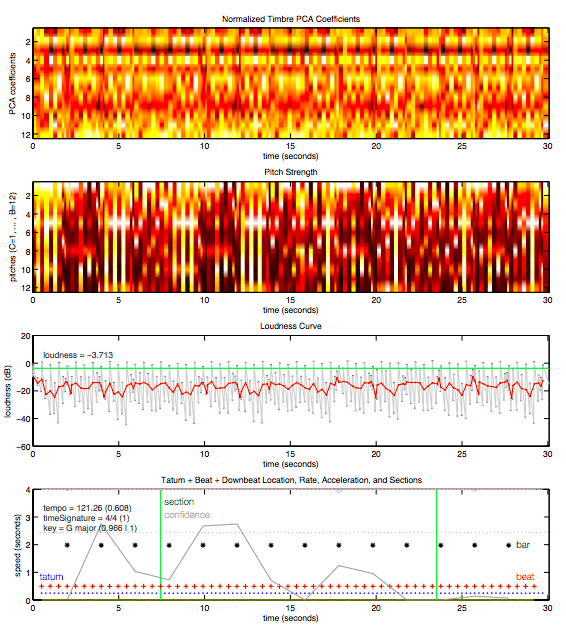
Raw Audio Models
หลาย ๆ ท่านอาจจะคิดว่า แค่ 2 model ข้างต้นนั้นก็สามารถวิเคราะห์ข้อมูล ของเพลงและ user ได้อย่างมีประสิทธิภาพแล้ว แต่ Spotify ได้เพิ่มในส่วนของ Raw Audio Model เพื่อเพิ่มความแม่นยำในส่วนการแนะนำเพลงให้มีความแม่นยำมากที่สุด และ Raw Audio Model นั้นยังสามารถที่จะเปิดประสบการณ์ฟังเพลงใหม่ ๆ ให้กับ user ได้อีกด้วย