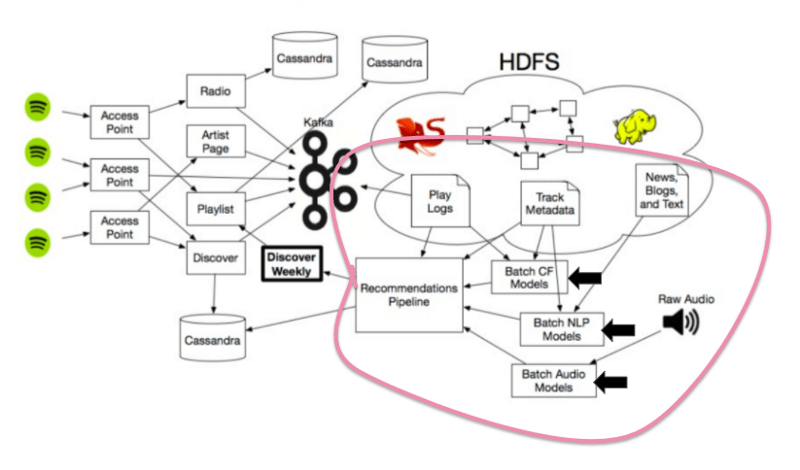
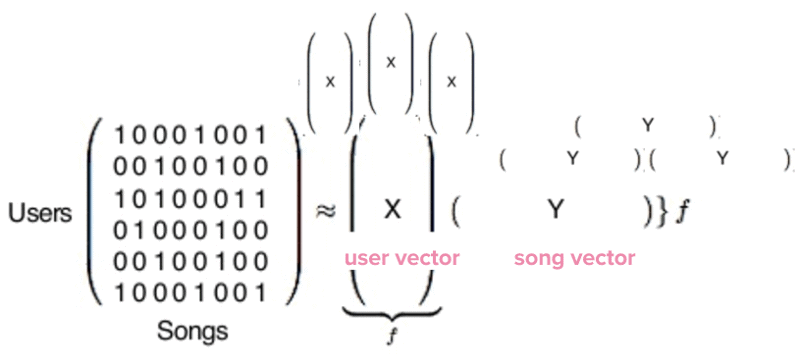
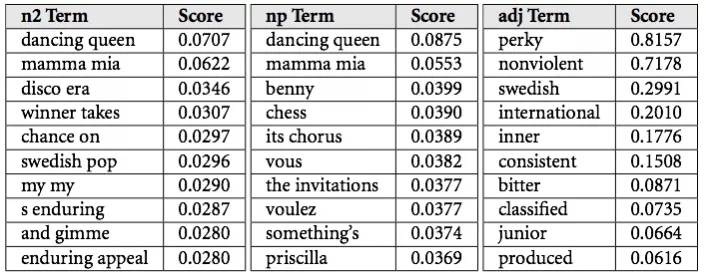
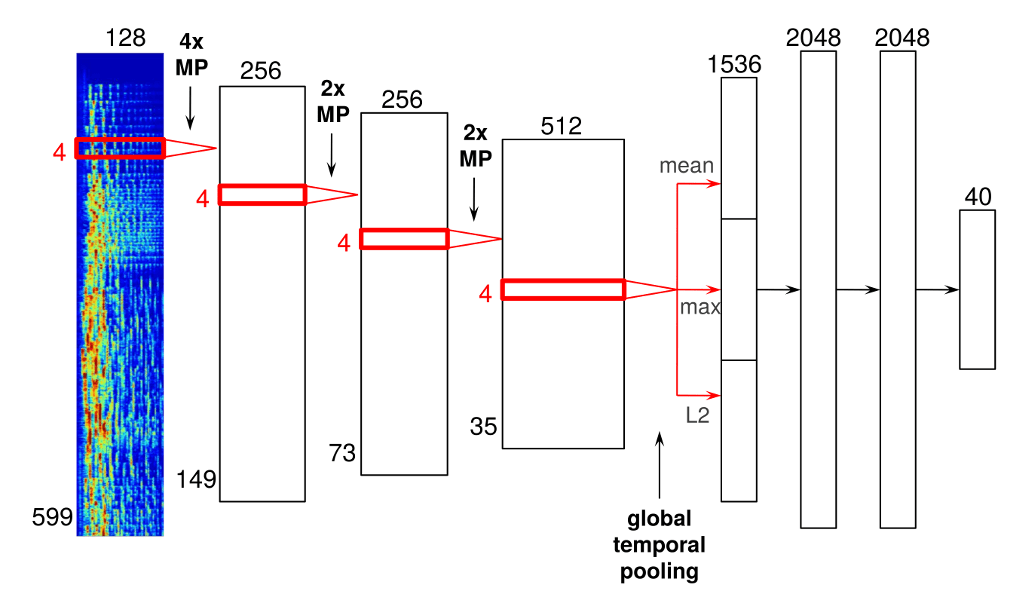
ต้องบอกว่ากระแสของ AI นั้นมาแรงจริง ๆ ในช่วงนี้ ทำให้ผู้ที่เกี่ยวข้องที่เป็นบุคลลากรด้าน AI ทั้งนักวิจัย รวมถึงวิศวกรต่าง ๆ ที่มีความสามารถทางด้าน AI เป็นที่ต้องการจากบริษัทยักษ์ใหญ่ของ silicon valley ไม่ว่าจะเป็น google , microsoft , apple หรือ facebook ซึ่งล้วนแล้วต่างมี project ที่เกี่ยวข้องกับ AI กันแทบทั้งสิ้น
แต่ไม่ใช่เฉพาะบริษัทยักษ์ใหญ่เท่านั้น เหล่า startup เล็ก ๆ ก็ให้ข้อเสนอที่เย้ายวนใจสำหรับบุคคลากรด้านนี้เหมือนกัน ไม่ว่าจะเป็นรูปแบบของหุ้น ซึ่งอาจจะทำให้เป็นเศรษฐีได้หากบริษัท startup เล็ก ๆ เหล่านั้นประสบความสำเร็จแบบบริษัทรุ่นพี่ขึ้นมาจริง ๆ เหมือนที่ google , facebook เคยทำได้ในอดีต
ต้องบอกว่าการแข่งขันทางด้านการแย่งตัวบุคคลากรนั้น ค่อนข้างรุนแรง เนื่องจากมีพนักงานที่มีคุณสมบัติด้าน AI ที่เป็นไปตามความต้องการของบริษัทเหล่านี้อยู่ไม่มาก จึงต้องมีการแย่งชิงตัวกัน โดยมีข้อเสนอเงินรายได้จำนวนมหาศาลเพื่อเป็นสิ่งล่อใจในการแย่งชิงตัวบุคลากรเหล่านี้
ซึ่งต้องบอกว่าเหล่าบริษัทยักษ์ใหญ่ใน silicon valley เดิมพันค่อนข้างสูงกับเทคโนโลยี AI ไล่มาตั้งแต่ ระบบการสแกนหน้าผ่าน smartphone เทคโนโลยีทางด้าน healthcare รวมไปถึง ในอุตสาหกรรมยานยนต์ ที่กำลังมุ่งสู่ยานยนต์ไร้คนขับ ซึ่งกำลังเดิมพันด้วยจำนวนเงินที่น่าตกใจ ทำให้รายได้ของพนักงานเหล่านี้สูงขึ้นตามไปด้วย
ซึ่งผู้เชี่ยวชาญด้าน AI ซึ่งรวมถึง ดอกเตอร์ที่เพิ่งจบปริญญาเอกมาใหม่ ๆ หรือแม้กระทั่งพนักงานที่มีประสบการณ์ไม่มากนัก แต่มีความรู้ด้าน AI ตามความต้องการของบริษัทยักษ์ใหญ่เหล่านี้ ก็สามารถเสนอค่าตอบแทนได้สูงถึง 300,000 – 500,000 เหรียญสหรัฐต่อปี รวมถึงให้ข้อเสนอทางด้านหุ้น เพื่อเป็นสิ่งล่อใจให้กับบุคคลากรเหล่านี้ให้เข้ามาอยู่กับบริษัทตัวเองให้ได้
สำหรับผู้ที่มีประสบการณ์การทำงานใน field AI มาบ้างแล้วนั้นก็ได้ค่าตอบแทนที่สูงขึ้นไปอีกในหลักล้านเหรียญสหรัฐต่อปี รวมถึงจำนวนหุ้นที่เป็นข้อเสนอก็จะมีจำนวนมากตามประสบการณ์ของพนักงานคนนั้น ๆ และรูปแบบการต่อสัญญานั้นบางครั้งก็คล้าย ๆ กับนักกีฬาอาชีพเลยก็ว่าได้ ซึ่งสามารถเรียกค่าตอบแทนเพิ่มมากขึ้นในการต่อสัญญาใหม่ โดยสัญญาอาจจะเป็นระยะสั้น เพื่อให้สามารถต่อรองเรื่องสัญญาใหม่ได้เร็วขึ้นนั่นเองเพราะมีหลายบริษัทที่คอยจะฉกตัวกันไปอยู่แล้ว เพราะความต้องการใน domain ดังกล่าวนั้นมีล้นมาก แต่บุคคลากรยังไม่พอต่อความต้องการ
ยิ่งไม่ต้องพูดถึงในระดับผู้บริหารที่มีประสบการณ์กับโครงการ AI นั้น บางรายอาจจะมีปัญหาถึงกับต้องเข้าสู่กระบวนการศาลกันเลยทีเดียวเช่น ในกรณีของ Anthony Levandowski ซึ่งเป็นลูกจ้างเก่าของ google ที่ได้เริ่มงานกับ google มาตั้งแต่ปี 2007 ได้รับค่าแรงจูงใจหรือ incentive ในการไปเซ็นสัญญาเข้าร่วมงานกับบริษัท Uber กว่า 120 ล้านเหรียญสหรัฐ ซึ่งต้องทำให้ทั้ง google และ Uber ต้องมีปัญหาขึ้นโรงขึ้นศาลกันเนื่องมาจากปัญหาเรื่องทรัพย์สินทางปัญญาที่อาจจะถูกละเมิดได้

Anthony Levandowski
มีปัจจัยเร่งไม่กี่อย่างที่ทำให้อัตราการจ่ายค่าจ้างของบุคคลากรด้าน AI นั้นถีบสูงขึ้นอย่างรวดเร็ว หนึ่งในนั้นคือ การแย่งตัวจาก อุตสาหกรรมรถยนต์ ที่กำลังพัฒนาในส่วนรถไร้คนขับ ซึ่งต้องการบุคคลากรแนวเดียวกันกับที่บริษัทยักษ์ใหญ่ทางด้าน internet ใน silicon valley ต้องการ ซึ่งส่วนของบริษัททางด้าน internet อย่าง facebook หรือ google นั้นต้องการแก้ปัญหาหลายอย่างที่ต้องใช้ AI ในการแก้เช่น การสร้างผู้ช่วย digital สำหรับ smart phone หรือ IoT device ที่อยู่ภายในบ้าน หรือการคัดกรองเนื้อหา content ที่ไม่เหมาะสมในระบบก็ต้องอาศัย AI ในการช่วยคัดกรอง ซึ่งการแก้ไขปัญหาเหล่านี้นั้นไม่เหมือนกับการสร้าง application mobile ธรรมดา ๆ ที่สามารถหาบุคคลากรได้ไม่ยาก แต่ต้องอาศัยความเชี่ยวชาญในด้าน AI เพื่อช่วยแก้ปัญหาเหล่านี้ให้ง่ายขึ้น
ต้องอาศัยเงินไม่ใช่น้อยหากจะสร้าง Lab ทางด้าน AI ตัวอย่างของ Deepmind ที่เป็น Lab ที่วิจัยทางด้าน Deep Learning ที่ถูก google aqquired ไปเมื่อปี 2014 มูลค่ากว่า 650 ล้านเหรียญสหรัฐนั้น มีรายจ่ายในการจ้างพนักงาน และเหล่านักวิจัยกว่า 400 คน สูงถึง 138 ล้านเหรียญสหรัฐ ซึ่งโดยเฉลี่ย ต่อคนสูงถึง 345,000 เหรียญสหรัฐต่อปี ซึ่งเป็นการยากที่บริษัทเล็ก ๆ จะสามารถแข่งขันเรื่องค่าจ้างกับบริษัทยักษ์ใหญ่ดังกล่าวได้
สำหรับความสำเร็จของงานวิจัยด้าน AI นั้นขึ้นอยู่กับ เทคนิคที่เรียกว่า Deep Neural networks ซึ่ง เป็น อัลกอรึธึมทางคณิตศาสตร์ ที่สามารถเรียนรู้ผ่านข้อมูลได้ด้วยตัวเอง เช่น การมองหารูปแบบของสุนัขนับล้านตัว ซึ่งทำให้ Neural Network สามารถเรียนรู้ที่จะจดจำรูปแบบของสุนัขได้ ซึ่งแนวคิดดังกล่าวนั้นต้องย้อนกลับไปตั้งแต่ยุค 1950 แต่มันยังคงอยู่ในรูปแบบของการศึกษาเท่านั้นจนกระทั่ง 5 ปีที่ผ่านมา ถึงได้เริ่มมีการนำมาประยุกต์ใช้ในงานจริง

googleplex
ในปี 2013 นั้น google , facebook รวมถึงบริษัทอื่น ๆ จำนวนหนึ่งนั้นได้ทำการเริ่มรับสมัครนักวิจัยเพียงไม่กี่คนที่เข้าใจถึง เทคนิคดังกล่าว ซึ่ง Neural Network ในตอนนี้สามารถที่จะช่วยจดจำใบหน้าในภาพถ่ายที่ post ไปยัง facebook หรือ สามารถระบุคำสั่งได้ใน Amazon Echo รวมถึงสามารถที่จะช่วยแปลภาษาต่างประเทศได้ผ่านบริการ skype ของ Microsoft ซึ่งล้วนแล้วแต่เกิดจากการพัฒนาทางด้าน Neural Network และมาประยุกต์ใช้กับธุรกิจจริงแทบทั้งสิ้น
ซึ่งการใช้ อัลกอริธึมทางคณิตศาสตร์ในลักษณะเดียวกันนั้น นักวิจัยกำลังทำการพัฒนารถยนต์แบบไร้คนขับ รวมถึงพัฒนาบริการของโรงพยาบาลในการวิเคราะห์โรค ผ่าน ภาพทางการแพทย์เช่น ภาพ X-Ray รวมถึงในวงการตลาดเงินหรือตลาดทุนนั้น ก็มีการพัฒนาหุ่นยนต์ที่คอยช่วยซื้อขายหุ้นแบบอัตโนมัติ ซึ่งนักวิจัยเหล่านี้ล้วนเป็นพวกมันสมองที่จบจากมหาวิทยาลัยดัง ๆ ของสหรัฐทั้งนั้น
Uber นั้นได้ทำการว่าจ้างนักจัยกว่า 40 คนจาก Carnegie Mellon เพื่อมาช่วยพัฒนายานยนต์ไร้คนขับของ Uber และ 1 ใน 4 ของนักวิจัยด้าน AI ชื่อดังได้ลาออกจากงานจากตำแหน่งศาสตราจารย์ที่มหาลัยสแตนฟอร์ด ส่วนในมหาวิทยาลัยวอชิงตันนั้น 6 ใน 20 ของนักวิจัยที่อยู่ในมหาลัย รวมถึงคณาจารย์ที่มีความเชี่ยวชาญกำลังลาออก และ ไปทำงานให้กับภาคเอกชนยักษ์ใหญ่ของอเมริกา
แต่ก็มีบางรายที่ออกไปอยู่กับองค์กรที่ไม่แสดงหาผลกำไร ตัวอย่าง Oren Etzioni ผู้ซึ่งลาออกจากตำแหน่งศาสตาจารย์จาก University of Washington เพื่อไปดูแล Allen Institute for Artifical Intelligence ซึ่งเป็นองค์กรที่ไม่แสวงหาผลกำไร
ส่วนบางรายก็ใช้รูปแบบการประนีประนอม Luke Zettlemoyer จาก University of Washington ได้มารับตำแหน่งที่ห้องทดลองทางด้าน AI ของ google ในเมือง ซีแอตเติล ซึ่งสามารถจ่ายเงินให้มากกว่าสามเท่าของรายได้เดิมของ Luke โดย google อนุญาติให้เขาสามารถสอนหนังสือต่อได้ที่ Allen Institute
ซึ่ง Zettlemoyes นั้นได้กล่าวไว้ว่า มีสถาบันการศึกษามากมายที่รองรับการทำงานทั้งสองรูปแบบ ที่สามารถแบ่งเวลาให้กับทั้งภาคเอกชน รวมถึง สามารถแบ่งเวลาส่วนนึงให้กับภาคการศึกษาได้ ปัจจัยหลักนั้นเกิดจากความแตกต่างอย่างสุดขั้วของรายได้ระหว่างการทำงานในภาคเอกชนกับภาคการศึกษา ซึ่งคนที่สามารถทำงานทั้งสองอย่างได้นั้น ก็เนื่องมาจากเขาสนใจในงานด้านวิชาการจริง ๆ
เพื่อเป็นการสร้างบุคคลากรรุ่นใหม่ทางด้าน AI ให้เพิ่มมากขึ้น บริษัทอย่าง google หรือ facebook นั้น ได้สร้าง class ที่สอนเนื้อหาเกี่ยวกับ “deep learning” รวมถึงเทคโนโลยีต่าง ๆ ที่เกี่ยวข้อง ให้กับพนักงานที่มีอยู่ เพื่อเป็นการสร้างบุคคลากรรุ่นใหม่ภายในบริษัทเอง รวมถึงการเปิด online course ให้กับพนักงานผู้ที่สนใจด้าน AI ได้เข้ามาเรียนรู้
ซึ่งแนวคิดพื้นฐานของ Deep Learning นั้นก็ไม่ได้ยากเกินไปที่จะเรียนรู้ ซึ่งอาศัยความรู้ทางด้านคณิตศาสตร์ที่เป็นพื้นฐานหลักของเหล่าวิศวกรในบริษัทเหล่านี้อยู่แล้ว แต่ การที่จะสร้างผู้เชี่ยวชาญด้านนี้จริง ๆ นั้นต้องอาศัย ความรู้ทางด้านคณิศาสตร์ชั้นสูง รวมถึงความรู้เฉพาะด้าน ซึ่งเป็นสิ่งจำเป็นสำหรับสาขาต่าง ๆ เช่น รถขับเคลื่อนอัตโนมัติ หรือ การวิเคราะห์ข้อมูลด้านสุขภาพ
แต่สำหรับบริษัทเล็ก ๆ นั้นการที่จะแข่งขันกับบริษัทยักษ์ใหญ่นั้นก็มีทางเลือกไม่มากนัก ก็ต้องมองหาทางเลือกอื่นที่ใช้งบประมาณไม่สูงเท่า เช่น บางบริษัทได้ว่าจ้าง นักฟิสิกส์ หรือ นักดาราศาสตร์ ที่มีทักษะทางคณิตศาสตร์ที่สามารถนำมาประยุกต์ใช้กับ AI ได้ หรือ มองหาพนักงานจากเอเชีย ยุโรปตะวันออก หรือ ที่อื่น ๆ ที่มีค่าแรงต่ำกว่าแทน
แต่เหล่าบริษัทยักษ์ใหญ่ อย่าง google , facebook หรือ Microsoft ก็ได้ทำการเปิดห้องทดลองด้าน AI ในต่างประเทศ เช่น Microsoft นั้นได้เปิดขึ้นที่ แคนาดา ส่วน google นั้นก็มีการจ้างงานเพิ่มขึ้นในประเทศจีนเหมือนกัน
ซึ่งสาเหตุต่าง ๆ เหล่านี้ล้วนแต่ทำให้ไม่แปลกใจว่าการขาดแคลนบุคคลากรด้าน AI นั้นคงจะไม่บรรเทาลงไปในเร็ว ๆ วันนี้อย่างแน่นอน เพราะการสร้างบุคคลากรด้านนี้ขึ้นมานั้นไม่ใช่เรื่องง่ายแต่อย่างใด มหาลัยที่เชี่ยวชาญที่สามารถสร้างบุคลากรที่มีคุณภาพออกได้ก็มีไม่มาก ซึ่งส่วนใหญ่ก็อยู่ในสหรัฐอเมริกา ซึ่งจากสาเหตุที่ demand และ supply ของบุคคลากรด้าน AI ยังไม่สมดุลในขณะนี้ ก็มีแนวโน้มที่รายได้ของบุคคลากรในด้านนี้ก็จะยังคงสูงขึ้นต่อไปเรื่อย ๆ อย่างแน่นอน
References : www.nytimes.com , www.paysa.com , qz.com